La classification est le processus qui consiste à attribuer de manière automatique une étiquette à des données. C'est la première chose que l'on apprend lors ce que l'on commence une formation sur le machine learning. En réalité, il s'agit d'une tâche non triviale, qui peut parfois nécessiter de nombreuses heures de travail pour un data scientist si celui-ci cherche absolument à trouver le modèle optimal pour son jeu de données. Dans le cas inverse ou il veut juste un modèle qui fonctionne et obtient une plutôt bonne performance, ce problème peut être résolu en quelque minute sous couvert que les caractéristiques du jeu de données soient réellement discriminantes pour le problème de classification à résoudre. Quoi qu'il en soit, l'utilisation de Weka pour résoudre ce genre de problème est d'une grande aide pour tous du fait de son interface simplifiée et de la rapidité avec laquelle l'on peut mettre en place un modèle en utilisant cette plateforme sans avoir même à écrire une seule ligne de code.
Dans cet article, nous verrons ensemble :
Comment charger un jeu de données
Comment vérifier à l'aide de Weka si les caractéristiques sont suffisamment discriminantes
Comment utiliser Weka pour choisir un algorithme de classification pour un problème donné
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
6.0,2.9,4.5,1.5,Iris-versicolor
5.7,2.6,3.5,1.0,Iris-versicolor
7.9,3.8,6.4,2.0,Iris-virginica
6.4,2.8,5.6,2.2,Iris-virginica
1- Ouvrir Weka
2- Cliquer sur Explorer
3- Cliquer sur "Open file..." et charger le fichier Iris.csv.
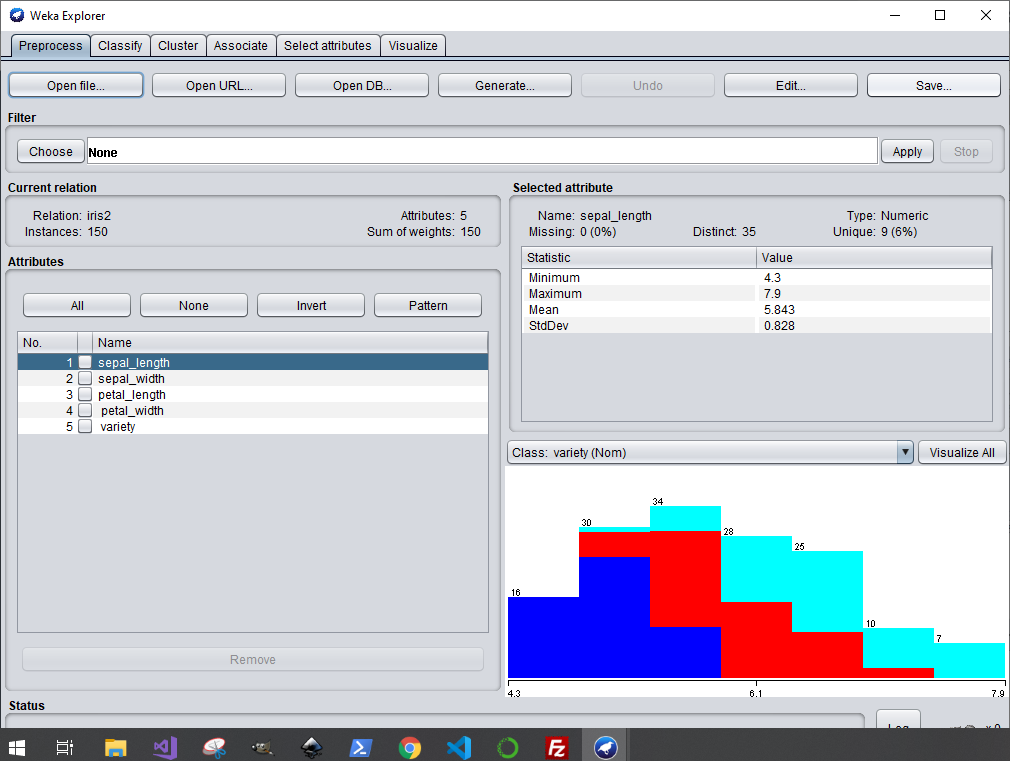
Cliquez sur "Visualize all"
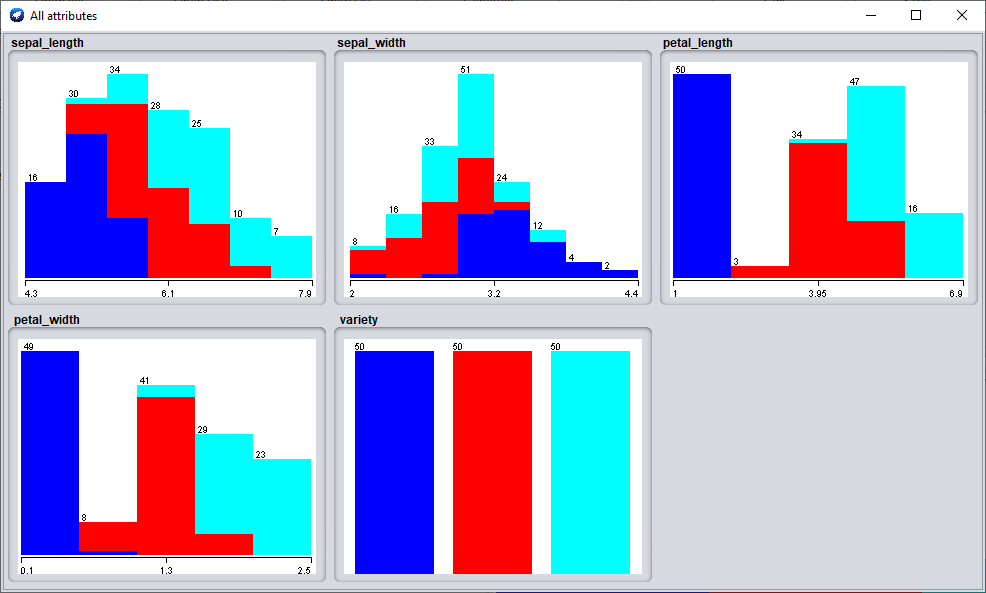
Cliguez sur l'onglet "Visualise"
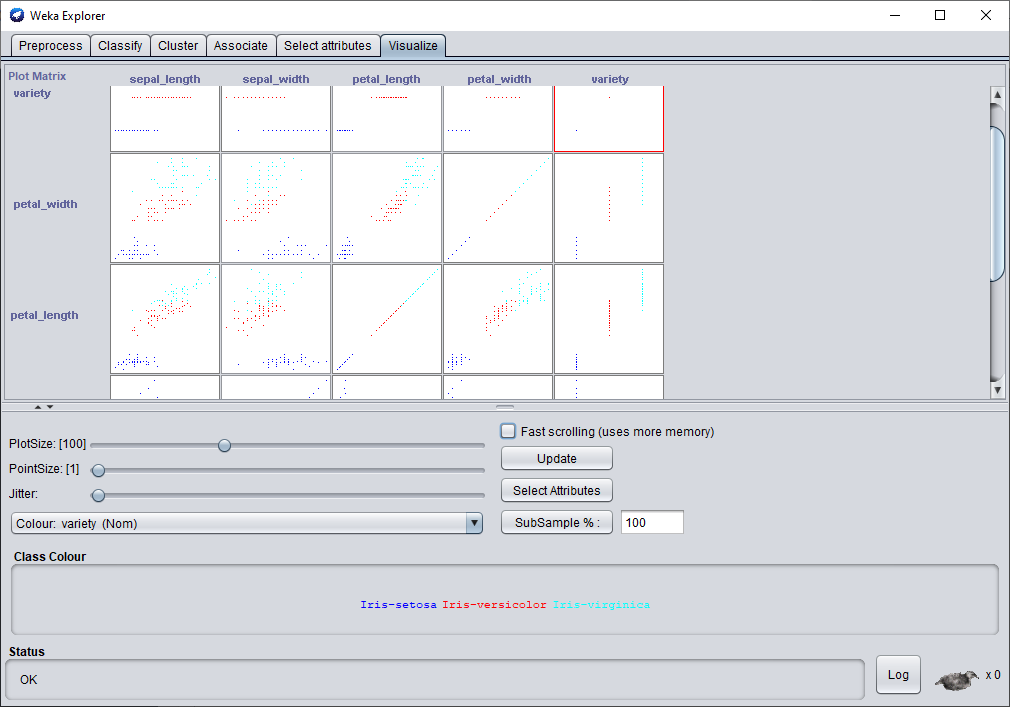
L'onglet visualise, nous permet de regarder de manière plus détaillée l’interaction qu'il y a entre les différentes classes selon leurs attributs. Nous remarquons sur le graphique ci-dessus que les attributs sépare bien les classes.
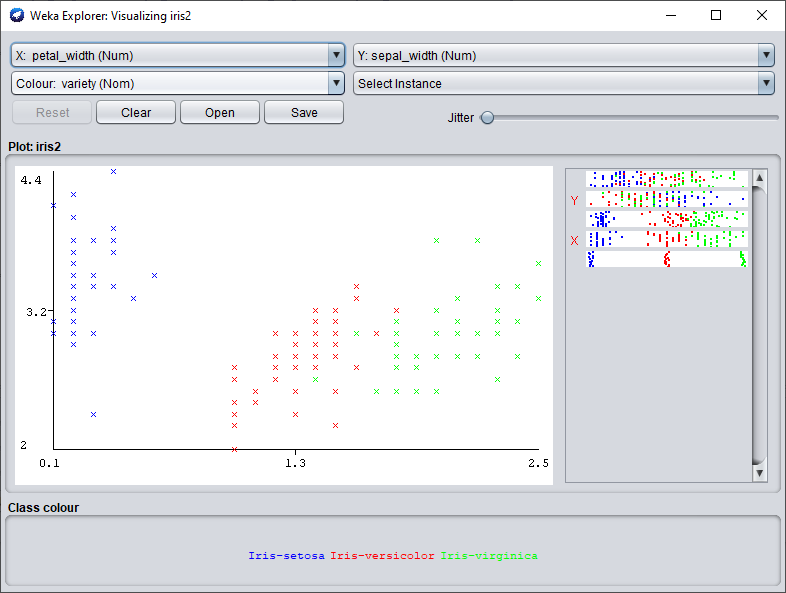
Maintenant que nous nous sommes assurés que les attributs permettaient de biens séparer les classes, nous pouvons passer aux choses sérieuses.
Cliquez sur l'onglet "Classify".
Cliquez sur Choose
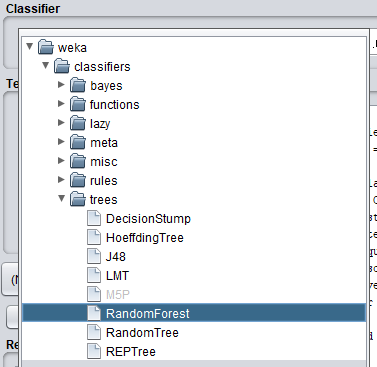
Une liste d'algorithme de classification vous ait proprosé. Vous êtes libre du choix de cet algorithme et je vous conseille de tous les tester pour bien vous imprégner de chacun d'eux. Personnellement dans cet article, je vais en tester 3 que j'aime bien et qui en général permette d'obtenir de très bonne performance. Il s'agit de l'arbre de décision JR48, le Random Forest et le perceptron multicouche.
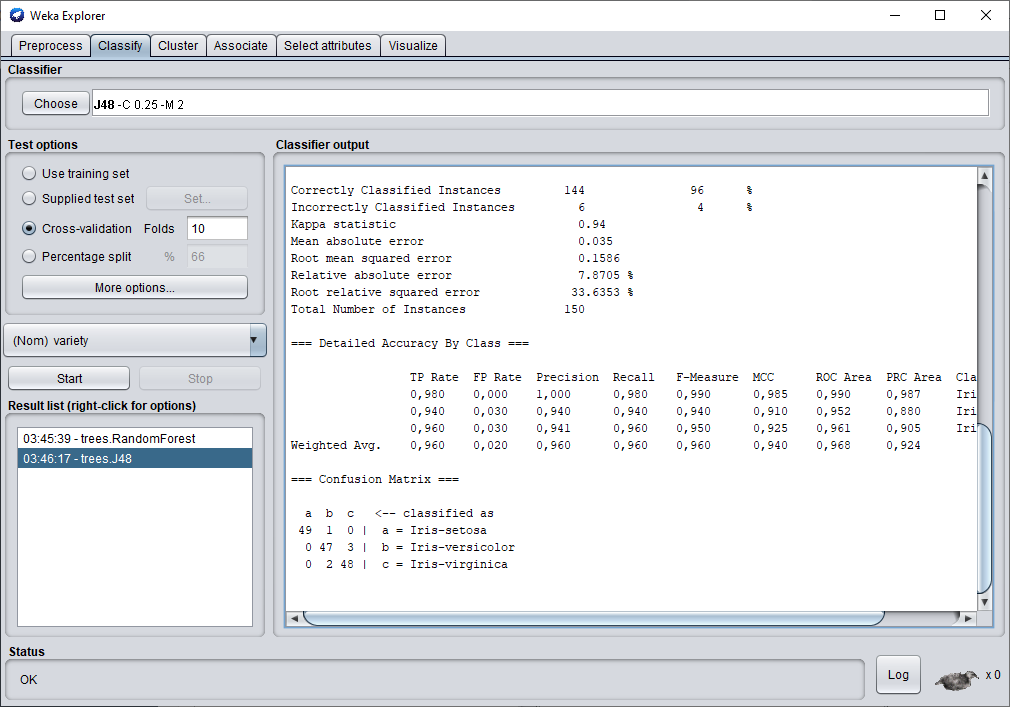
Pour commencer le test en cross-validation, il vous suffit de cliquer sur start et le test se lance alors. Avec l'arbre de décision JR48, nous obtenons une performance de 96 % d'exemple correctement classé. C'est plutôt pas mal. Une fois la classification terminée en scrollant la fenêtre vous pouvez voir l'arbre de décision et les critères qu'il a utilisés lors de sa classification.
Voyons maintenant ce que l'on obtient en utilisant le Random Forest.
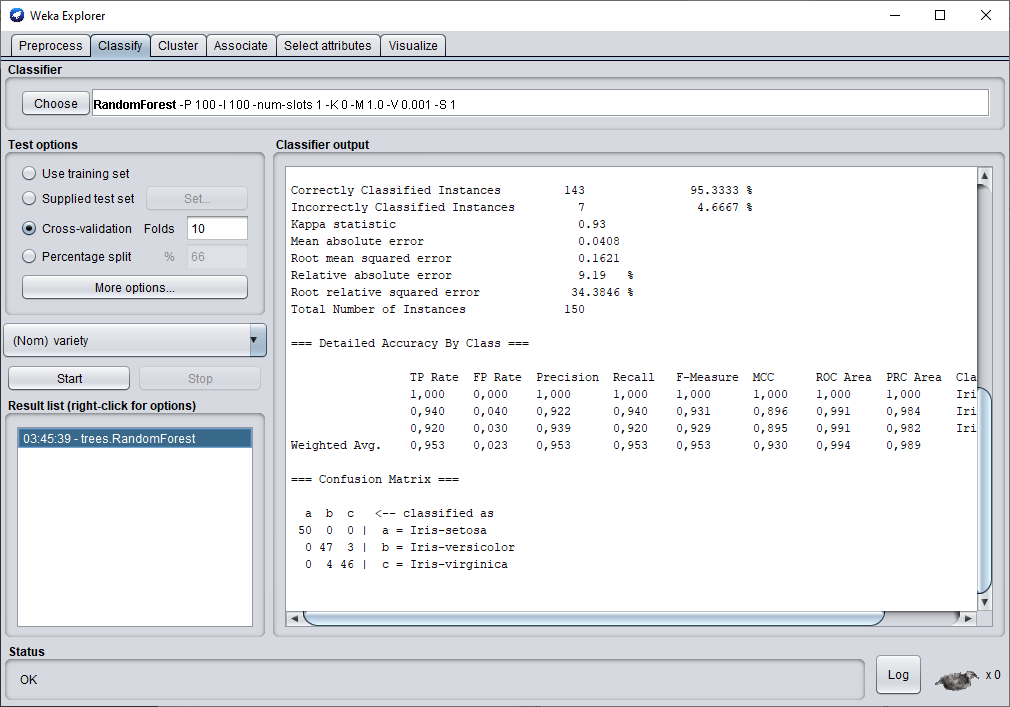
Nous obtenons une performance moins bonne qu'avec l'arbre de décision classique. Honnêtement, ce résultat est un peu surprenant quand on sait qu'un randomForest est un ensemble d'arbres de décision et que le principe reposant derrière ce modèle est de combiner plusieurs arbres décisionnels différents afin de prendre une meilleure décision. Dans ce cas-ci Weka n'affiche pas le modèle, car il est trop long d'afficher 100 arbres de décision.
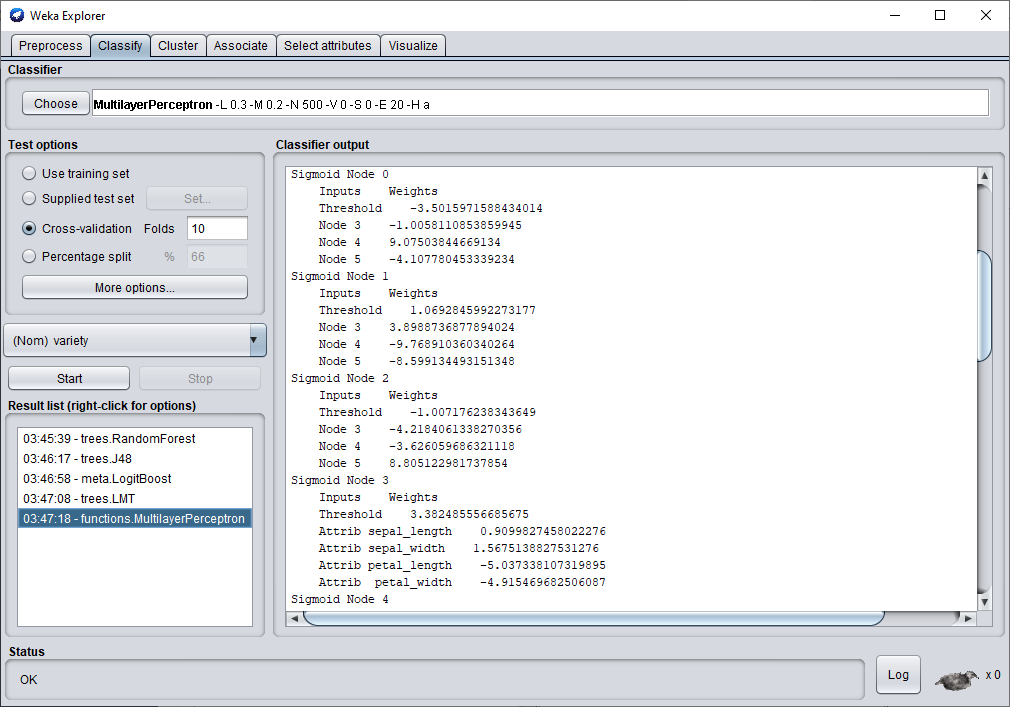
Nous finirons ce test avec le perceptron multicouche.
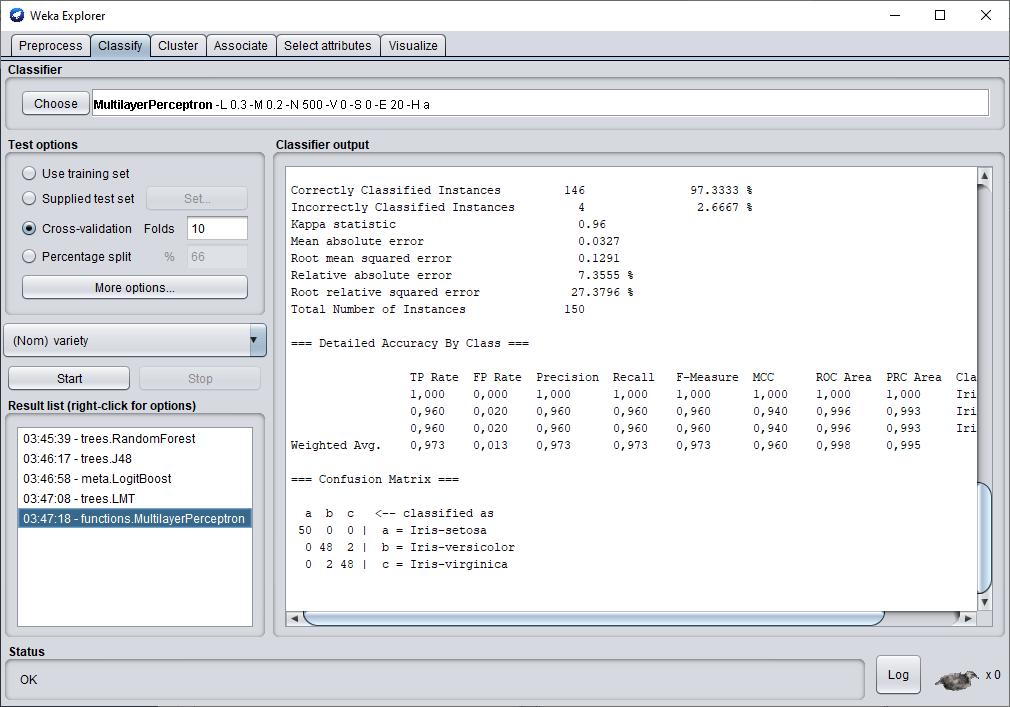
En utilisant le perceptron multicouche, nous avons réussi à obtenir un taux de classification de 97.33 %. Ce qui est supérieur au résultat obtenu par l'arbre de décision et par le random Forest. Par conséquent , c'est le modèle qui sera retenu pour ce jeu de données.