Dans cet série d’articles je vais vous partager ma propre expérience au sujet de « comment j’ai appris l’Intelligence artificielle » et de ce qu’il est important de savoir à son sujet.
Moi, André Junior, pour ceux qui ne me connaissent pas, j’ai commencé l’intelligence artificielle en 3e année de licence à l’université.
Dans un premier temps, les professeurs nous ont inculqué les bases des probabilités statistiques telles que les lois de probabilité usuelle,le théorème Bayes, la loi du chi2, etc.
Il faut savoir que si vous souhaitez faire de la recherche, les mathématique sont incontournable, et sont à la racine de tous les derniers algorithmes d’I.A en phase expérimentale dans les laboratoires de recherche. Par ailleurs dans un futur proche, j’écrirais un article sur qu’elles sont les bases mathématiques à maîtriser pour être un BOSS de l’I.A. Au programme, il y aura : Algèbre linéaire, calcul différentiel et intégral, probabilité statistique et optimisation.
Une fois que l’on avait vu toute les base de la proba et des stat, nous somme directement rentrée dans le vif du sujet en abordant des algorithmes d’I.A simples tels que les « k plus proche voisin » où encore « les fenêtres de parzen ».
Moi super emballé par le sujet, je faisais des recherches de mon côté sur comment construire une application de reconnaissance vocale et une Support vector machine.
Enfin, à partir du master 1, nous sommes rentrés dans des problématiques plus sérieuses telles que les réseaux de neurones, la reconnaissance faciale, la reconnaissance d’objet et de caractère, la fouille de données, qu’est-ce qu’Hadoop et comment l’utiliser, etc...
Et pour finir, mon stage de Master 2 a été une immersion dans le domaine de la recherche où je devais détecter à l’aide de l’IA et d’image satellitaire issues du satellite GOES-EAST des poussières présente dans l’air responsable de problèmes de santé sur le territoire des Antilles.
Maintenant en doctorat, je me consacre qu’à des problématiques de reconnaissance d’organismes végétaux.
Vous l’aurez donc remarqué, mon parcours dans l’IA a tout d’abord été très généraliste puis il s’est spécialisé aux applications de l'intelligence artificielle dans le domaine de l’image.
Concrètement une I.A, c'est un en ensemble de briques logicielles (ligne de codes) qu’un développeur va assembler dans un programme afin de simuler un raisonnement complexe, voire un raisonnement humain…
À partir de là une question légitime à se poser est qu’elles sont les différents types de brique logicielle qu’il est possible d’utiliser ?
Il y a principalement 5 briques élémentaires : la classification, la régression, le clustering, la réduction de dimensionnalité et la génération.
La classification est la brique la plus utilisée de l’I.A.
Le but de la classification est de prédire un résultat en fonction d’une observation.
Imaginons que nous ayons plusieurs photos d’animaux et que nous souhaitons construire une I.A capable de reconnaître des animaux. Nous pouvons alors dire que dans ce cas, une observation est une photo d’animal et un résultat est l’espèce d’un l’animal. Un réseau de neurones convolutif illustrant cette problématique est représenté ci-dessous :
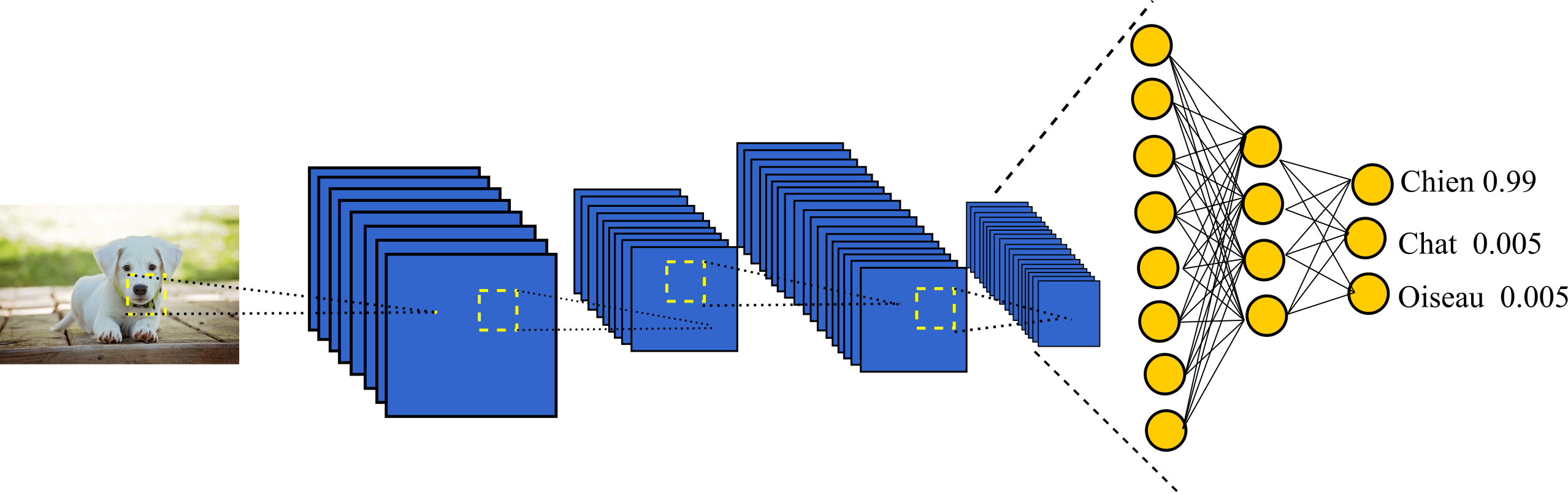
Supposons maintenant que nous soyons dans le cas d’un jeu vidéo, les observations seraient alors la situation actuelle à l’écran (une capture d’écran) et le résultat serait l’action à effectuer ( sauter , courir, monter, fuir, attaquer, etc..)
Je tiens à souligner que l’I.A apprend uniquement par l’exemple. C’est pourquoi la première étape lors ce que l’on souhaite créer une I.A est de disposer d’un lot d’observations et d’associé à chacune des observations un résultat.
Mais je vous rassure de nombreux lots d'observations et leurs résultats sont disponibles en ligne sur des sites tels que :
-kaggle.
Une brique de type classification peut être mise en place en utilisant l’un des algorithmes suivants :
-Réseau de neurones convolutif (réseau de neurones adapté aux traitements d’images)
-LSTM Network (réseau de neurones adapté aux traitements des séquences)
La régression ressemble énormément à la classification. Elle consiste à déterminer une valeur quantitative à partir de données qui sont à la fois quantitatives et qualitatives.
Par exemple, l’on utilisera un algorithme de régression si l’on cherche à déterminer le poids d’un chat en fonction de sa taille, son espèce et de son âge.
Autre exemple, dans un jeu vidéo, il est possible de déterminer une direction dans laquelle se diriger sous forme d’un angle compris entre 0 et 360 en fonction de la position des ennemis grâce à la régression.
Vous pouvez implémenter une régression en vous servant des différents algorithmes suivant :
À la différence de la classification et de la régression, le clustering n’a pas besoin d’un résultat pour être mis en oeuvre. Son but est de regrouper les données selon leurs ressemblances.
Par exemple, dans le cas d’un site e-commerce, il est possible d’utiliser le clustering pour regrouper des groupes d’article qui sont fréquemment achetés ensemble et ensuite de proposé à l’utilisateur des articles en fonction de ces groupes et de son panier actuel.
Les algorithmes faisant partie de cette catégorie sont :
- k-means
La réduction de dimensionnalité est comme son nom l’indique une série d’algorithmes visant à extraire des informations pertinentes à l’intérieur de données brutes.
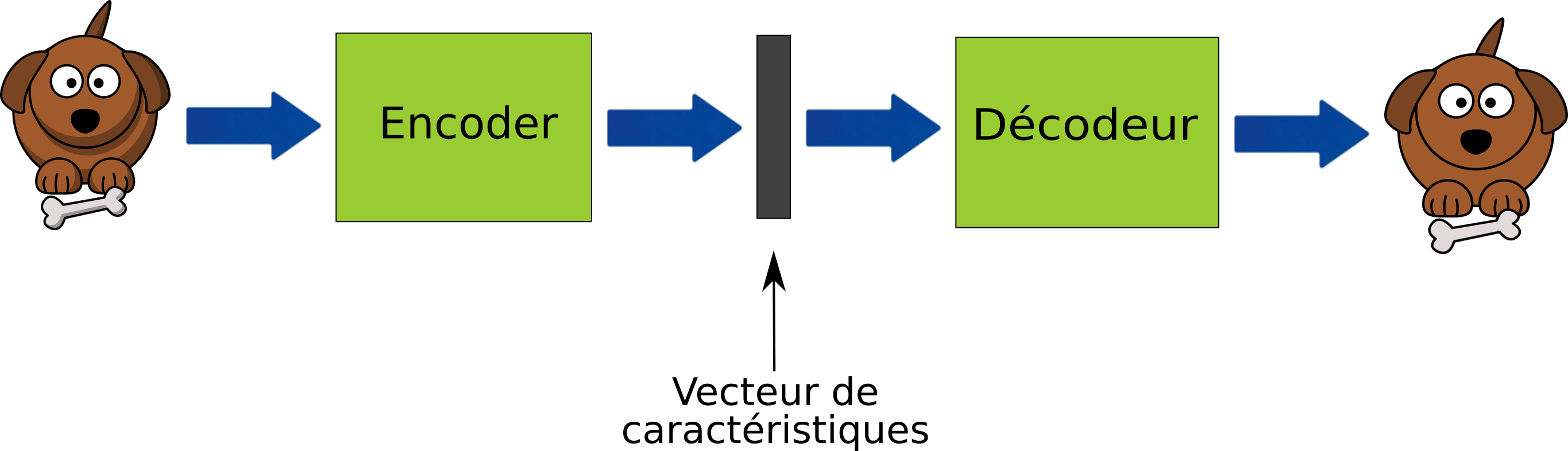
Par exemple, dans le schéma suivant où le fonctionnement d’un auto-encodeur est représenté vous remarquerez qu’au début de la chaine il y a une image de chien, elle est ensuite au milieu de la chaine réduite en un vecteur de caractéristique c’est-à-dire en une suite de valeurs numériques synthétisant l’information comprise à l’intérieur de l’image du chien, c'est une représentation réduite du chien. Puis dans un deuxième temps, un décodeur va se servir de cette représentation réduite pour reconstruire l’image du chien.
Les algorithmes utilisés la plupart du temps dans cette catégorie sont :
-Analyse en composante principale
-Machines de Botlzmann restreinte
Pour finir, la sous-brique la plus récente et actuellement la plus prometteuse en I.A est la génération. Il s’agit de pouvoir à partir d’information telle qu’une phrase (ex : une fleur avec un coeur bleu et des pétales blanche) être capable de générer les données (ex : images) correspondantes. Si vous voulez en savoir plus sur ce type d’algorithme, vous pouvez vous reporter à l’article suivant : Text to Image Synthesis Using Generative Adversarial Networks (en anglais) qui explique comment à partir de texte l’on peut générer des images.
L’algorithme le plus populaire actuellement pour la génération de données est le Generative Adversarial network (GAN).
Il y a de nombreuses applications aux réseaux génératifs telles que générer des visages de personnes n’existant pas, générer des images de chambre, de voitures, de pokémon, etc…. Et même créer de la musique. Il est possible de voir quelques applications de ce réseau de neurones dans la vidéo ci-dessous :
Il existe 5 briques élémentaire qui peuvent faire partie une I.A, la classification, la régression, le clustering, la réduction de dimensionnalité et la génération. C’est la manière dont vous agencées ces différents éléments qui définira fonctionnement final de votre I.A. La quantité de données que vous avez en votre possession et votre expertise du domaine permettra à l’I.A d’avoir le comportement espéré sans faire d’erreurs.
Nous verrons plus en détail dans les jours à venir, les différents éléments que j’ai présentés dans cet article. Mais si vous voulez en savoir plus sur les différents points abordés dans cet article vous pouvez lire mon article sur le deep-learning.