Quand on débute dans le machine learning, on commence souvent par l'apprentissage supervisé et très souvent pas la classification. Probablement, car c'est le type d'apprentissage le plus simple à comprendre, mais également le plus facile à implémenter "from scratch". En effet, en 2 heures de TP, n'importe quel étudiant motivé qui n'y connait rien au machine learning peut implémenter l'algorithme des plus proches voisins.
Personnellement, si je ne me trompe pas, le premier jeu de données que j'ai classifié remonte à 7 ans (2013) et c'était le jeu de données Iris.csv. Que je recommande d'ailleurs pour débuter. Ce jeu très utilisé pour l'enseignement à l'avantage de présenter des données discriminatives, c'est-à-dire donc la séparation entre les classes est visuellement distincte quand l'on affiche les données dans un graphique. Ce qui est plutôt très pédagogique. Mais en plus, il permet directement de comprendre l'intérêt pratique du machine learning. Il y a aussi le jeu de données Wine qui est pas mal. Dans tous les cas, si vous souhaitez trouver un jeu de données pour vous exercer au machine learning, il y a le site UCI repository qui contient une tonne de jeux de données différents pour s'entraîner.
Dans cet article je vous présenterais :
Ce qu'est une matrice de confusion
Qu'elles sont les mesures qu'on peut extraire et calculer à partir de cette dernière.
Comment obtenir une matrice de confusion en python avec le jeu de données Iris
Comment obtenir une matrice de confusion avec l'utilitaire Weka (pour qui veulent aller vite sans se casser la tête)
Une matrice de confusion est un simple de tableau qu'on obtient à la fin de la phase de test d'un modèle de classification sur un jeu de données. Dans celle-ci, vous retrouverez des informations sur les classes qui ont été ou pas confondues. Prenons par exemple la matrice de confusion ci-dessous. Elle a été générée en se servant du logiciel Weka sur le jeu Iris.
=== Confusion Matrix ===
a b c <-- classified as
49 1 0 | a = Iris-setosa
0 47 3 | b = Iris-versicolor
0 2 48 | c = Iris-virginica
Avant de l'analyser, je vais courtement présenter le jeu de données Iris. Il s'agit d'un jeu de données qui a été constitué à partir de mesures prélevées des fleurs appartenant à 3 espèces différentes (Iris-setosa, Iris-versicolor et Iris-virginica). Il est constitué au total de 150 exemples avec 50 exemples pour chaque espèce. Les quatre mesures qui ont été prélevées sont : la longueur de sépale, la largeur de sépale, la longueur de pétale et la largeur de pétale.
Nous remarquons l'indicatif "classified as" qui est propre à Weka et qui signifie en français "classifier comme" et je dirais même "classifié comme étant" , ensuite il y a trois choix a, b, et c et à droite il y a non seulement à quoi corresponds les trois lettre a, b et c mais aussi la vraie classe. Donc dans cette matrice de confusion, nous pouvons lire que 49 exemples du jeu de données ont été classés comme Iris-setosa et le sont bien. Un exemple a été classé comme Iris-versicolor mais en réalité est Iris-setosa.
À partir de cette matrice de confusion, de nombreuses mesures peuvent être extraites telles que :
TP Rate « true positive » : nombre de fois que la classe prédite par le classifieur est la vraie classe.
FP Rate « false positive » : nombre de fois que la classe prédite par le classifieur ne correspond pas à la vraie classe.
FN Rate « false negatif » : nombre de fois que la classe non prédite par le classifieur correspond à la vraie classe .
La précision il s’agit du rapport entre les vrais positifs (TP) sur les (vrai positif) et les faux positifs.
Le rappel est le ratio entre les vrais positifs sur les vrais positifs + les faux négatifs. Il s’agit de la capacité du classifieur à trouver tous les exemples positifs.
Le score "F-beta" est une moyenne harmonique pondérée entre la précision et le recall. Sa meilleure valeur est 1 et sa pire valeur est zéro.
Exemple pour Iris :
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
0,980 0,000 1,000 0,980 0,990 0,985 0,990 0,987 Iris-setosa
0,940 0,030 0,940 0,940 0,940 0,910 0,952 0,880 Iris-versicolor
0,960 0,030 0,941 0,960 0,950 0,925 0,961 0,905 Iris-virginica
Weighted Avg. 0,960 0,020 0,960 0,960 0,960 0,940 0,968 0,924
Extrait du logiciel Weka
Il faut premièrement l'installer, vous pouvez voir comment y arriver dans cet article : Weka Tutoriel.
Puis il faut l'ouvrir:
1- Ouvrir Weka
2- Cliquer sur Explorer
3- Cliquer sur "Open file..." et charger le fichier Iris.csv.
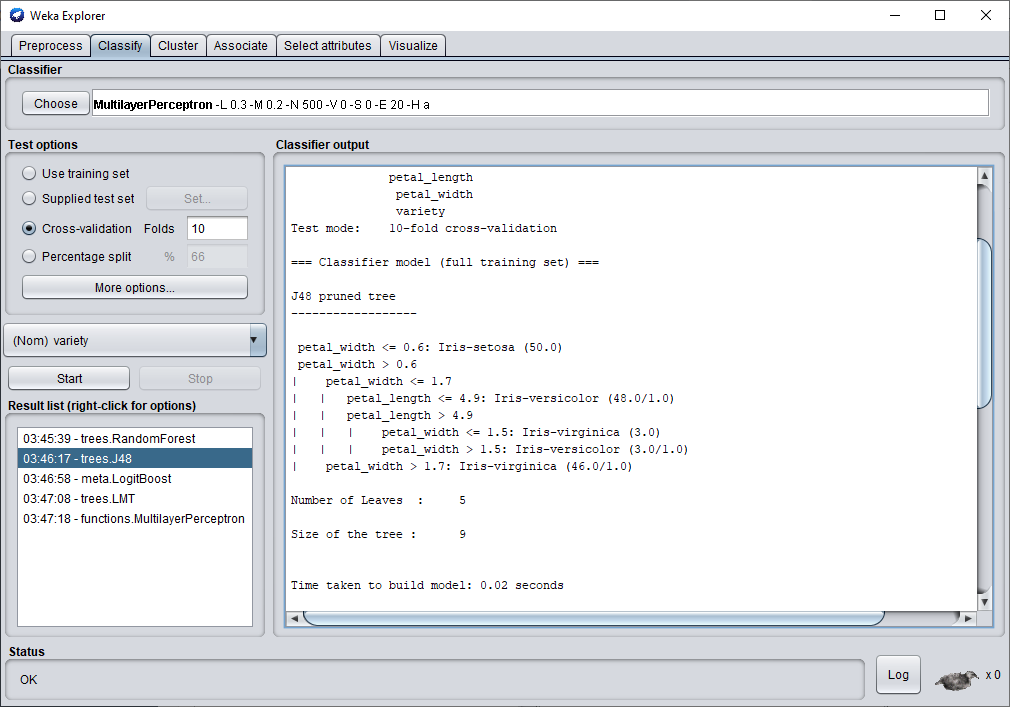
Cliquez sur l'onglet "Classify".
Cliquez sur Choose
Une liste d'algorithme de classification vous est proposée. Vous êtes libre du choix de cet algorithme et je vous conseille de tous les tester pour bien vous imprégner de chacun d'eux. Personnellement dans cet article, je vais en tester 3 que j'aime bien et qui en général permette d'obtenir de très bonne performance. Il s'agit de l'arbre de décision JR48, le Random Forest et le perceptron multicouche.
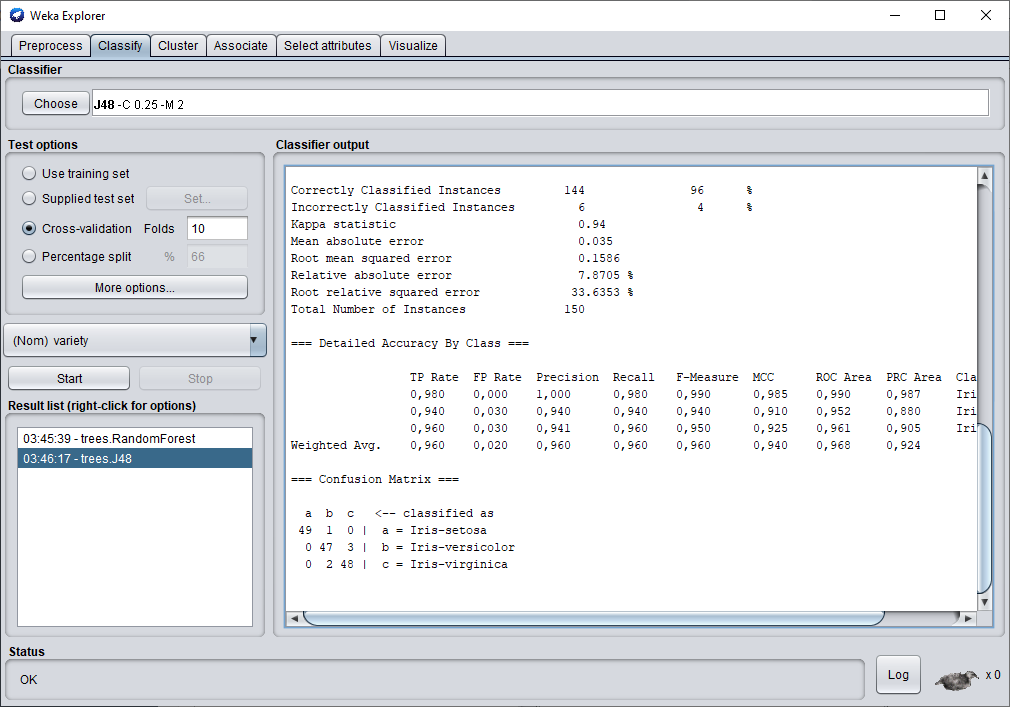
Pour commencer le test en cross-validation, il vous suffit de cliquer sur start et le test se lance alors. Avec l'arbre de décision JR48, nous obtenons une performance de 96 % d'exemple correctement classé. C'est plutôt pas mal. Une fois la classification terminée en scrollant la fenêtre vous pouvez voir l'arbre de décision et les critères qu'il a utilisés lors de sa classification.