Actuellement (en 2020 du moins), la classification supervisée est l'approche de machine learning
Elle permet de résoudre un large panel de problème pratique de la vie réelle tel que :
La détection de défaut d'usinage, de fraude, de maladie
Le tri automatique de courrier, de document ou encore de vidéo
La reconnaissance d'images ( ex : reconnaissance de caractères, plantes, pollens, etc...)
et de manière générale, toutes les
D'ailleurs, si tu as suivi les actualités ces derniers temps, tu auras sans doute probablement entendu parler des grosses moutures du Deep learning tels que OpenAI ou Deep Mind qui réalise des choses assez surprenantes telles que :
Ces performances sont possibles grâce à la classification supervisée.
OpenAI et DeepDream utilisent des réseaux de neurones entrainés sur de nombreux exemples de parties de jeux et à chaque fois que ce réseau doit faire un choix il génère toutes les combinaisons de plateau possible puis les classe en deux
les configurations perdantes et les configurations gagnantes.
Ils choisissent par la suite dans les plateaux qu'il a classifiés comme gagnant,
le meilleur plateau possible.
Autrement dit, ces réseaux de neurones capables de battre les plus grands champions du monde ne font que du classement, du tri ou encore de la classification supervisée si tu préfères.
Tu peux d’ailleurs apprendre à faire la même chose qu'eux pour le jeu du morpion en suivant ce tuto : Morpion python : Créer un morpion et son I.A qui apprend toute seule à jouer.
Mais sache que les réseaux de neurones ne sont pas les seuls algorithmes utilisés pour faire de la classification supervisée il en existe de nombreux tels que les arbres de décision ou encore la régression linéaire. Tu en connaîtras quelque un un si tu vas au bout de cet article.
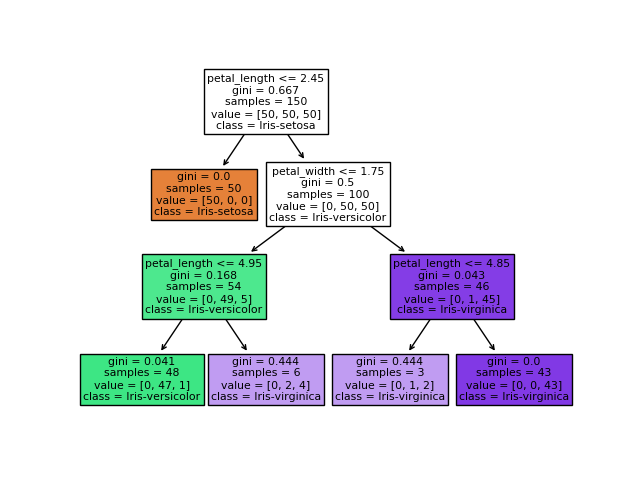
Image d'un arbre de décision, un des algorithmes régulièrement utilisés en classification supervisée.
Dans cet article, j'aborderais avec toi :
Ce qu'est la classification supervisée
Comment un algorithme de classification supervisée fonctionne ?
Quelles sont les principales causes d'échec d'un apprentissage supervisé ?
Qu'est-ce que le rapport de classification et à quoi sert-il ?
Divers exemples d'algorithmes de classification supervisée
Une brève introduction à la classification non supervisée
La classification supervisée consiste à
dont on ne connaît pas la catégorie.
Pour ce faire,
ou très proches des données que l'on souhaite classer.
C'est d'ailleurs de la que vient le supervisée du mot classification supervisée, car l'humain a d'ores et déjà trié et classé les données sur lesquelles va s'entraîner le classifieur.
Dans le cas ou les données d'entrainement ne sont ni trier ni classé, l'on parle alors de
Supposons que l’on souhaite développer une application capable de distinguer les 3 types de fleurs présentées ci-dessous.

Pour ce faire, il faut créer un classifieur.
Il s'agit d'une sorte une boîte noire à laquelle l'
et qui en sortie nous
.
Pour atteindre cet objectif, le classifieur doit être une fonction ou un modèle mathématique auquel quand l'on soumettra les entrées produira une sortie la plus proche que possible de celle désirée.
Il est impossible de construire une fonction généraliste qui fonctionnerait pour toutes les entrées et pour toutes les sorties.
C'est pourquoi il va falloir construire cette fonction automatiquement en utilisant les données d'entrée et de sortie d'exemples ou d'échantillons que l'on a du problème que l'on souhaite résoudre.
En clair, nous allons procéder à ce qu'on appelle couramment en machine learning à l'entraînement du classifieur.
Cette procédure se déroule comme suit :
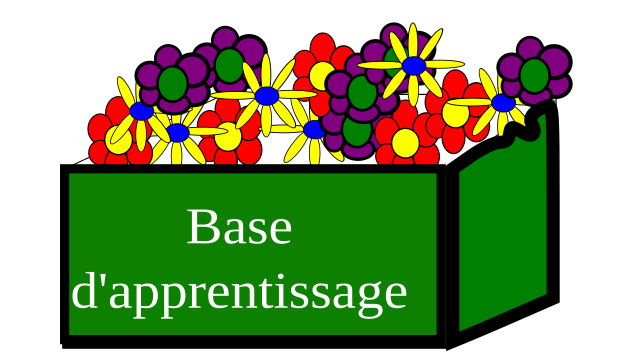
À partir des données que l'on a du problème, 2 lots sont constitués aléatoirement:
un lot d'apprentissage que l'on nommera base d'apprentissage
un lot de test que l'on nommera base de test.
Le premier lot servira à entraîner le classifieur tandis que le second servira à tester le classifieur.
Lors de l'entraînement, les exemples sont soumis un à un dans un ordre aléatoire au classifieur.
Pour chaque exemple soumis, deux cas sont possibles.
Le premier est le classifieur trouve la réponse correcte, dans ce cas-là c’est parfait, l’on passe alors à l’exemple suivant (cf : Illustration ci-dessous).
Le second cas est le cas la réponse du classifieur est incorrect, dans ce cas l’algorithme d’entrainement répare le classifieur afin qu’il sorte la bonne réponse et l’on peut alors passer à l’exemple suivant (cf : Illustration ci-dessous).
Après cette phase dite d’entraînement du classifieur, vient alors une phase de test. Durant cette phase, des exemples qui n’ont jamais été vus par le classifieur durant son entraînement lui sont soumis.

Si les réponses du classifieur sont correctes, l’on considère qu’il a été bien entrainé, à l’inverse si elles sont incorrectes le classifieur est mal entrainé et il est alors important d’en trouver la cause.
Plusieurs cas de figure sont alors possibles :
1- Les données avec lesquelles l'on a entrainé le classifieur ne sont pas suffisamment descriptives pour trouver la classe
2-Le classifieur est tellement entraîné sur les données d'apprentissage qu'il fait du "par coeur" en test et donc se trompe sur de nouvelles données. Cela s'appelle le "surapprentissage".
3- La Base d'apprentissage diverge trop de la base de test. Dans certains cas, il se peut que votre base d’entraînement ne soit pas représentative de la réalité et soit donc bien différente de celle de test. Il est donc important pour prévenir ce genre de déconvenue et de s’assurer qu’on soit en possession d’une base d’apprentissage représentative de la réalité de l'application que l'on souhaite en faire.
4-Sous-entraînement. L'entraînement du classifieur a été arrêté en cours de route, conséquence il n'a pas eu assez de temps pour comprendre et s'adapter au problème. Ce problème est le plus simple à résoudre puisqu'il vous suffit de rajouter des itérations lors de l'entraînement du classifieur pour ce faire.
Maintenant que nous avons vu ce qu’est la classification, nous allons voir ce qu'est un rapport de classification.
À l'issue de la classification, bien souvent, pour de nombreux framework, bibliothèque ou encore logiciel de machine learning, il vous sera possible d'obtenir un rapport de classification.
Ce dernier permet de rapporter énormément d'information sur le résultat de la classification et parfois même des pistes pour améliorer ce dernier.
Ci-dessous, vous pouvez voir un extrait du rapport de classification de Weka, un des logiciels les plus populaires et polyvalents de machine learning.
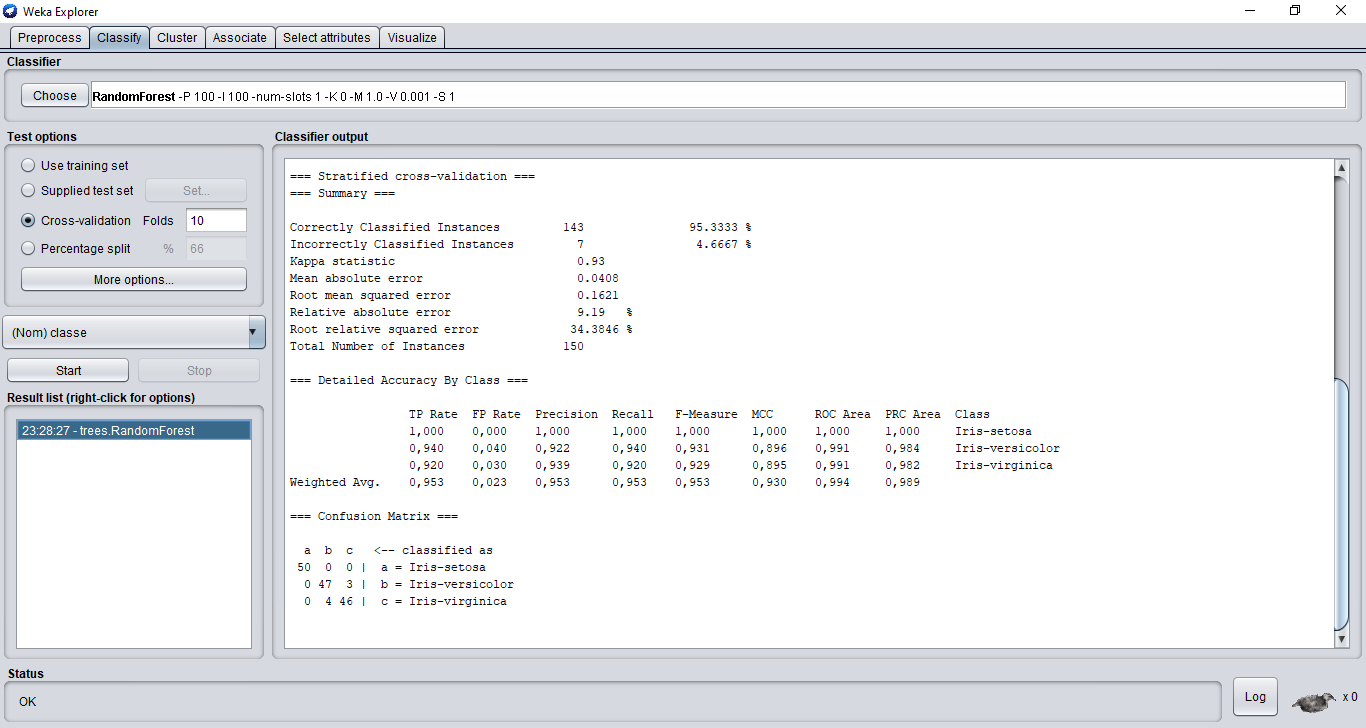
Le rapport de classification se décompose comme suit :
Tour d'abord, un résumé "Summary" avec les principales mesures nous est proposé.
Dans le cas de la classification, seules les 4 premières mesures nous intéressent.
Il s'agit du nombre et du taux d'exemple bien classé, du nombre et du taux d'exemple mal classé.
L'erreur moyenne absolue, l'erreur moyenne carrée absolue et les autres erreurs sont des mesures dédiées à la résolution de problème de régression, c'est pourquoi je ne les expliquerais pas dans cet article.
Dans un second temps, comme vous pouvez le voir, dans la section "Detailed Accuracy By class" , le rapport de classification donne des informations détaillées sur chaque classe.
Ce sont :
TP Rate« true positive » : nombre de fois que la classe prédite par le classifieur est la vraie classe.
FP Rate« false positive » : nombre de fois que la classe prédite par le classifieur ne correspond pas à la vraie classe.
FN « false negatif » : nombre de fois que la classe non prédite par le classifieur correspond à la vraie classe .
La précision il s’agit du rapport entre les vrais positifs (TP) sur les (vrai positif) et les faux positifs.
Le rappel est le ratio entre les vrais positifs sur les vrais positifs + les faux négatifs. Il s’agit de la capacité du classifieur à trouver tous les exemples positifs.
Le score "F-beta" est une moyenne harmonique pondérée entre la précision et le recall. Sa meilleure valeur est 1 et sa pire valeur est zéro.
À la fin du rapport, vous retrouverez généralement la matrice de confusion. Il s'agit d'une matrice qui permet de connaître les classes qui ont été confondues lors de la phase de test.
Exemple :
a b c <-- classé comme
50 0 0 | a = Iris-setosa
0 47 3 | b = Iris-versicolor
0 4 46 | c = Iris-virginica
En analysant la matrice de confusion présentée ci-dessus, nous remarquons que 3 exemples ont été classés comme étant des "Iris-Virginica" alors qu'ils étaient des "Iris versicolores" et 4 exemples ont été classés "versicolor" alors qu'en réalité ils étaient des "virginica".
La méthode des k-plus proches voisins consiste à chercher dans une base de données l’exemple le plus proche de celui que l'on est en train de traiter et ensuite à donner comme réponse à l'utilisateur la solution de cet exemple.
Un arbre de décision est un outil d'aide à la décision représentant un ensemble de choix sous la forme graphique d'un arbre. Les différentes décisions possibles sont situées aux extrémités des branches.
Le Random Forest, que partagent l’ensemble des méthodes ensemblistes est assez intuitive : plutôt que d’avoir un estimateur très complexe censé tout classifier à lui seul, on en construit plusieurs de moindre qualité individuelle qui possèdent une vision réduite du problème. Ensuite, on réunit l’ensemble de ces estimateurs pour avoir une vision globale.
Un neurone artificiel possède m+1 entrées, auquel l’on soumet m signaux que nous noterons x1,x2... xm et m+1 poids noté w0,w1….wm poids.
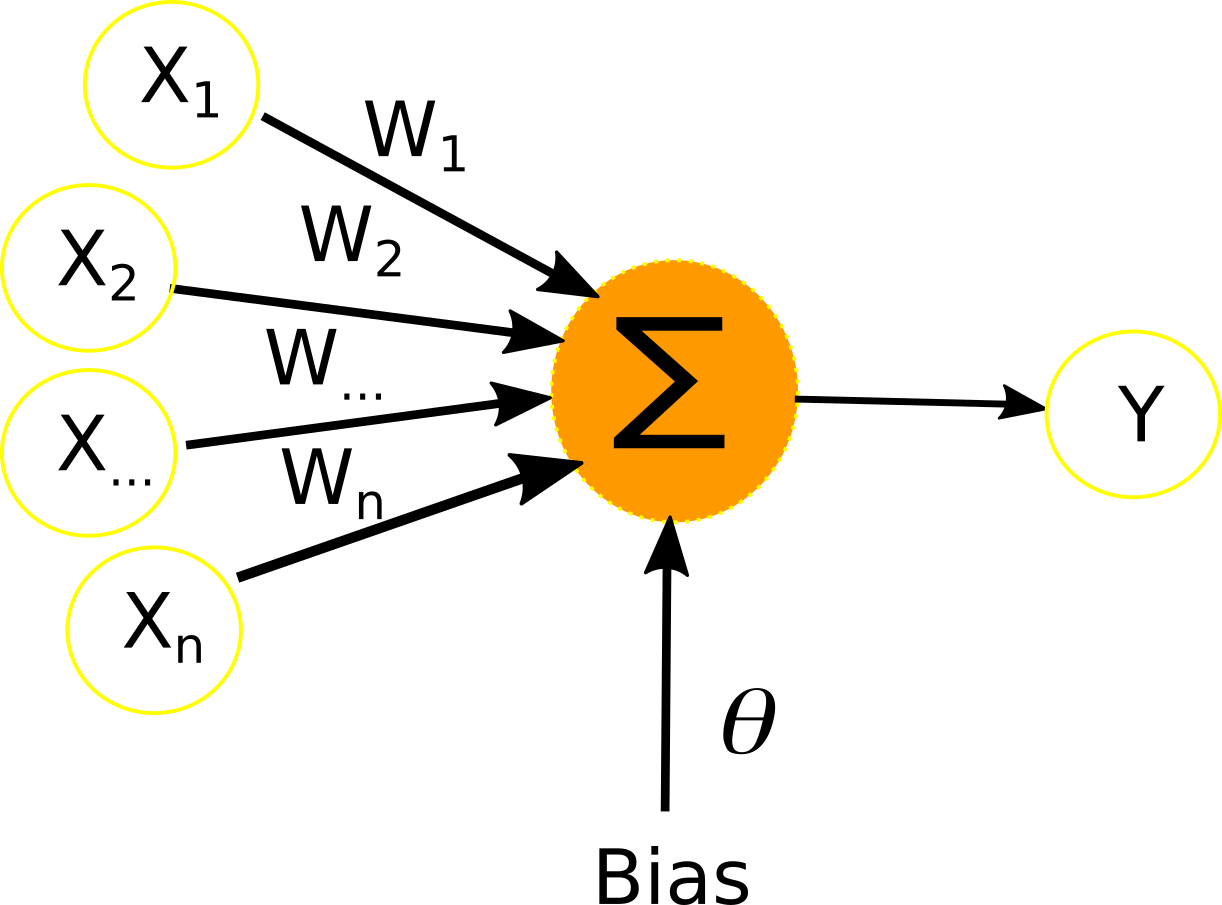
Un perceptron multicouches est un ensemble de neurones formels connectés entre eux suivant la topologie montrée dans la figure ci-dessous. Il est composé d’une couche d’entrée, de n couches cachées et d’une couche de sortie. Chaque neurone prend pour signal d’entrée l’ensemble des sorties des neurones de la couche qui précède la couche de celui-ci.

Afin d’obtenir la sortie que nous souhaitons, il est nécessaire de modifier les poids de chacun des neurones formels composant le réseau. De nombreux algorithmes (adam,sgd,rmsprop,…) existent afin de fixer les poids optimaux, mais de manière générale ceux-ci reposent tous sur le même concept. Il s’agit de la rétropropagation de l’erreur par le gradient.
Le boosting est une technique d'apprentissage qui vise à rendre plus performant un système d'apprentissage faible. Pour ce faire, le système d'apprentissage est entraîné successivement sur des échantillons d'apprentissage en surpondérant les exemples difficiles à apprendre.
Trois idées fondamentales sont à la base des méthodes de boosting probabilistes:
1. L'utilisation d'un comité d'experts spécialistes que l'on fait voter pour atteindre une décision.
2. La pondération adaptative des votes par une technique de mise à jour.
3. La modification de la distribution des exemples disponibles pour entraîner chaque expert, en surpondérant au fur et à mesure les exemples mal classés aux étapes précédentes.
L'algorithme le plus pratiqué s'appelle AdaBoost
À la différence de la classification supervisée, la classification non supervisée plus connue sous le nom de "clustering" n’a pas besoin des classes des exemples pour être mise en oeuvre.
Son but est de regrouper les données selon leurs ressemblances.
Par exemple, dans le cas d’un site e-commerce, il est possible d’utiliser le clustering pour regrouper des groupes d’article qui sont fréquemment achetés ensemble et ensuite de proposé à l’internaute des articles en fonction de ces groupes et de son panier actuel.
- k-means
-Mean-shift
-Expectation-maximisation
-DBSCAN