Le perceptron est la brique élémentaire de départ qui a permis l’invention des premiers réseaux de neurones. À l’origine, celui-ci avait été conçu dans les laboratoires du Cornell Aeronautical par Frank ROSENBLATT en 1957 afin de modéliser le fonctionnement d’un neurone humain. Sur le schéma ci-dessous, nous pouvons observer le perceptron. Il possède n entrées (X1 à Xn), ces entrées sont généralement des nombres entiers où réels transmis au perceptron. À chacune des entrées X est associée un poids W qui servira au calcul de la sortie Y. Enfin, une connexion bias est ajoutée, car celle-ci est nécessaire au bon fonctionnement du perceptron. Le calcul effectué pour obtenir la sortie Y est le suivant :
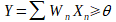
Quand il s’agira de classification binaire, l’on dira que si Y est supérieur à θ, la classe vaut 1 sinon elle vaut zéro.
Schéma du perceptron :
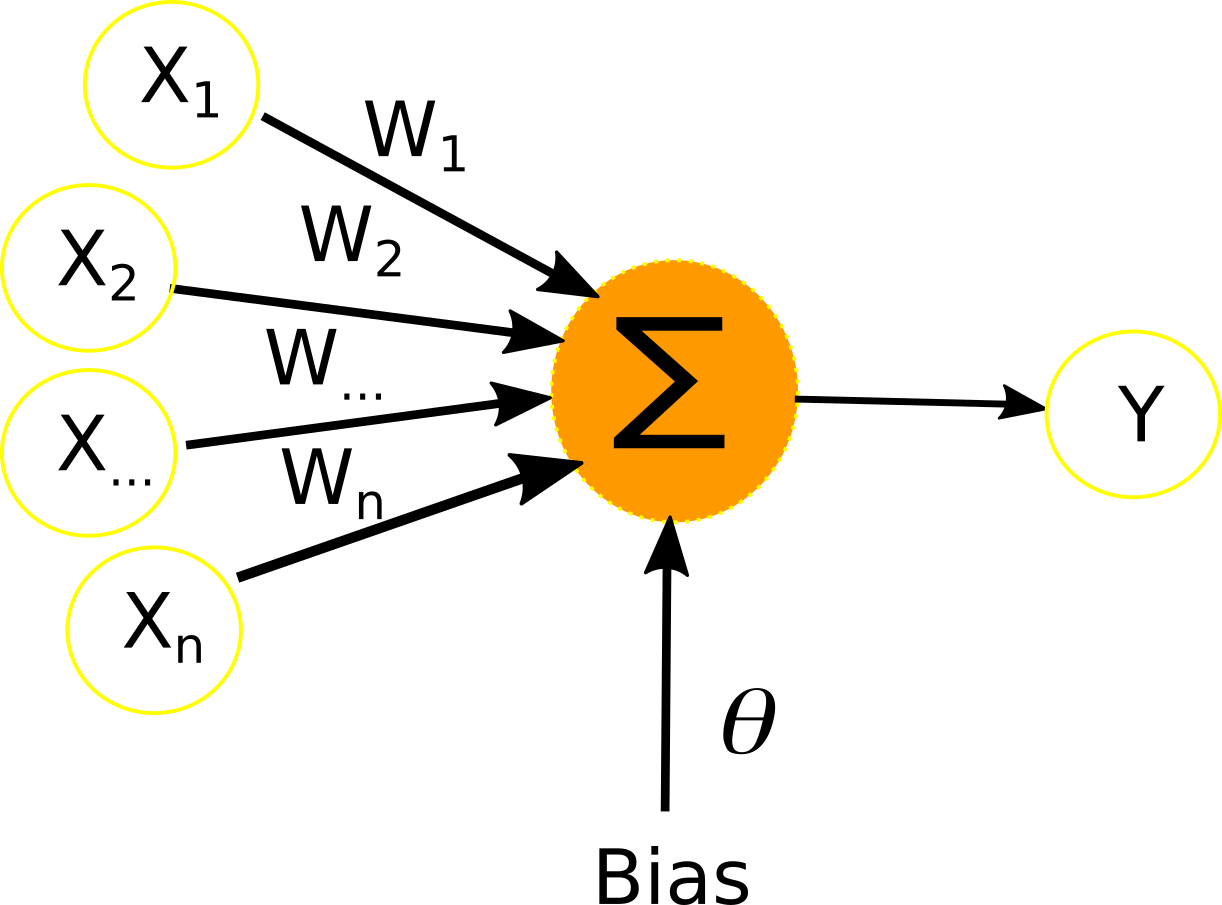
Entraîner un perceptron est relativement simple. Supposons que nous ayons une base B de k exemple, chaque exemple est composé de n mesure X1 à Xn qui sont de nombres réels et d’une sortie c qui est le résultat que l’on souhaite que le perceptron obtienne. L’algorithme qui permet d’entrainer le perceptron est le suivant :
Entrée : Une base constituée B de k exemple
1- Initialisation aléatoire de tous les poids du réseau
2- Choix aléatoire d’un exemple i de la base B
3-Calcul de la sortie Y pour cet exemple avec la formule
4- Actualisation des poids en utilisant la formule : W_j = W_j + (c – Y ) * x_j
Le perceptron multicouche où encore multilayers perceptron en anglaisest le premier réseau de neurones à avoir trouvé de nombreuses applications pratiques telles que la reconnaissance de fleurs, la détection de fraudes, etc.. Il peut être utilisé pour toutes tâches de classification supervisées. De nos jours, il est l’un des modèles les plus populaires, et est implémenté par de nombreuses librairies telles que TensorFlow, Weka, Scikit-Learn, etc.
Schéma du perceptron multi-couche :

L’on peut voir les neurones du perceptron multicouche comme une multitude de perceptron connectés entre eux.La particularité topologique de ce réseau est que tous les neurones d’une couche sont connectés à tous les neurones de la couche suivante. Chaque neurones a donc n entrées, n étant le nombre de neurones présent dans la couche précédente, et une sortie qui est envoyée à tous les neurones de la couche suivante.
À chaque connexion neuronale est associé un poids W, comme pour les entrées du perceptron. Le calcul de la sortie d’un neurone se fait selon la fonction d’activation qui a été choisie.
Il existe différentes fonctions d’activation possible pour un neurone. Remarquons qu’il est important que la fonction d’activation soit dérivable, car il sera impossible de calculer l’erreur individuelle de chaque neurone utilisé si la fonction utilisée n’est pas dérivable. Actuellement, la fonction la plus populaire est la fonction Relu, car elle nécessite peu de ressource processeur pour être calculée et permet d’obtenir des résultats similaires à la fonction sigmoïde qui est très précise.
Lors du choix de la fonction d’activation, le programmeur regardera le succès qu’obtient le réseau de neurones dans la tâche qui lui à été attribué, mais aussi le temps d’exécution de la fonction d’activation.
Les réseau de neurones ne fonctionne qu'avec des valeurs numérique. Le perceptron multi-couche n'échappe pas à cette règle c'est pourquoi si vous traité du texte, il vous faudra prélablement le transformer. Cela peut se faire par exemple en utilisant la représentation Bag of Word qui consiste à construire l’histogramme des occurrences de l’apparition de mots dans un texte. Où encore d'autres représentations plus évoluées telles que Latent Dirichlet Allocation où Word2Vec.
De plus, dans la cas ou vous traiter des données numérique, il est nécessaire soit de les normaliser ou de les standardiser de tels sorte à ce qu'elle toute vos données soit comprises entre 0 et 1. Car si ce n'est pas le cas, après entraînement le réseau de neurones ne fonctionnera pas.
De nombreux algorithmes permettent d'entraîner ce type de réseau de neurones tels que AdaGrad, RMSProp, Stochastics Gradient Descent (SGD), AdaDelta, Adam où encore Rectified Adam (Radam).
Cependant, tous ces algorithmes sont inspiré du premier algorithme d'entraînement du MLP nommé la rétropropagation du gradient.
Entrée : Une base B de k exemple
1- Les poids du réseau de neurones sont initialisés de manière aléatoire.
2- Un exemple dans la base B est sélectionné aléatoirement
3-Sa sortie est calculée
4- Les poids de tous les neurones du réseau sont corrigés. Pour cela, pour tous les neurones, en partant du dernier :
Une fois entraîné, il vous suffit de soummettre une entrée au réseau et en sortie du réseau vous obtiendrez le résultat souhaité.
[1] https://en.wikipedia.org/wiki/Types_of_artificial_neural_networks
[2] https://en.wikipedia.org/wiki/Recurrent_neural_network
[3] http://www.asimovinstitute.org/neural-network-zoo/
[4] http://people.idsia.ch/~juergen/rnn.html
[5] https://dataanalyticspost.com/Lexique/reseaux-de-neurones-recurrents/
[6] https://fr.wikipedia.org/wiki/R%C3%A9seaux_antagonistes_g%C3%A9n%C3%A9ratifs
[7] https://arxiv.org/pdf/1805.00676.pdf