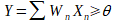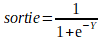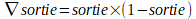Les réseaux de neurones artificiels sont de nos jours le modèle de machine learning le plus répandu et le plus populaire dans la communauté.
Cette popularité, trouve son explication dans la
Car bien souvent, figurez-vous que ceux-ci ne sont simplement que
Auxquelles, il suffit d'envoyer les données à ces derniers pour obtenir le résultat souhaité et obtenir de bonnes prédictions, qu'il s'agit de trier des fleurs, de détecter des maladies, de prédire les évolutions du marché boursier ou tout simplement de faire de la reconnaissance vocale ou faciale.
Il existe de nombreux types de réseaux de neurones, mais les plus importants à connaître sont ceux majoritairement utilisés en industrie tels que :
le perceptron multicouches
le réseau convolutif de neurones
les réseaux de neurones récurrents et plus particulièrement le Long-Short Term Memory network ou LSTM (c'est plus court).
Les auto-encodeurs
et pour finir les réseaux antagonistes génératifs plus connus sous le nom de GAN.
Chacun des réseaux de neurones, cité précédemment dispose d'une
qui lui est propre et qui lui accorde des propriétés spécifiques par rapport à l'application que l'on souhaite en faire.
C'est pourquoi ils répondent les uns des autres à des besoins totalement différents !
Par exemple, impossible de reconnaître une image avec un réseau LSTM ! Car il est dédié à l'étude des séries temporelle.
Ou encore impossible des données sonore brutes avec un perceptron multi-couche. En effet celui-ci du fait de sa simplicité est incapable de gérer des données brutes qui ne sont pas préalablement prémâchées.
Dans cet article, nous verrons ce qu'est :
un perceptron multicouche
un réseau de neurones convolutif
un auto-encodeur
un réseau de neurones récurrent
un réseau antagoniste génératif.
Le perceptron multicouche appartient à ce que l'on appelle à une catégorie de réseau de neurones couramment appelé dans la communauté :
(Feedfoward neural network : en anglais). Pour faire court, disons qu'il y a plusieurs manières d'organisé un réseau de neurones et il se trouve, que les réseaux de neurones à propagation avant sont :
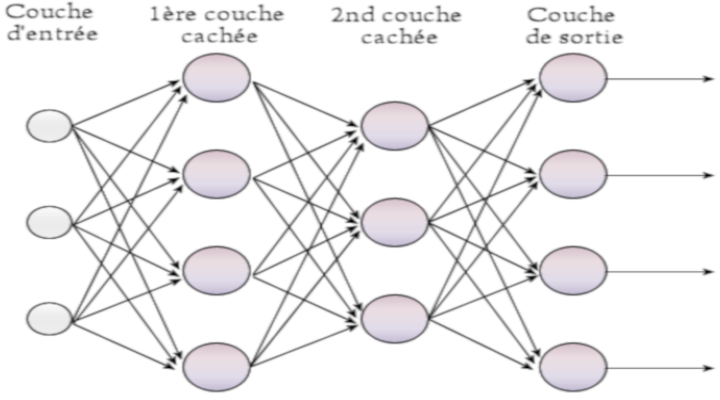
Ou plutôt comme le dirait un expert, l'information va circuler
C'est à la couche d'entrée que sont soumises les données du problème à résoudre.
C'est la couche de sortie qui renvoie à son utilisateur la prédiction du réseau.
Les autres couches se situant entre ces deux couches sont appelées :
Elles sont directement responsables du traitement effectué par le réseau de neurones qui permet d'obtenir les prédictions.
À la base du perceptron multicouche, se trouve :
Il s'agit de la brique élémentaire de départ qui a permis l’invention des premiers réseaux de neurones.
Ce dernier a été conçu en 1957 par Frank ROSENBLATT en 1957.
Son but à l'époque derrière cela:
En gros, voilà à quoi ressemble ce neurone artificiel :
Schéma du perceptron :
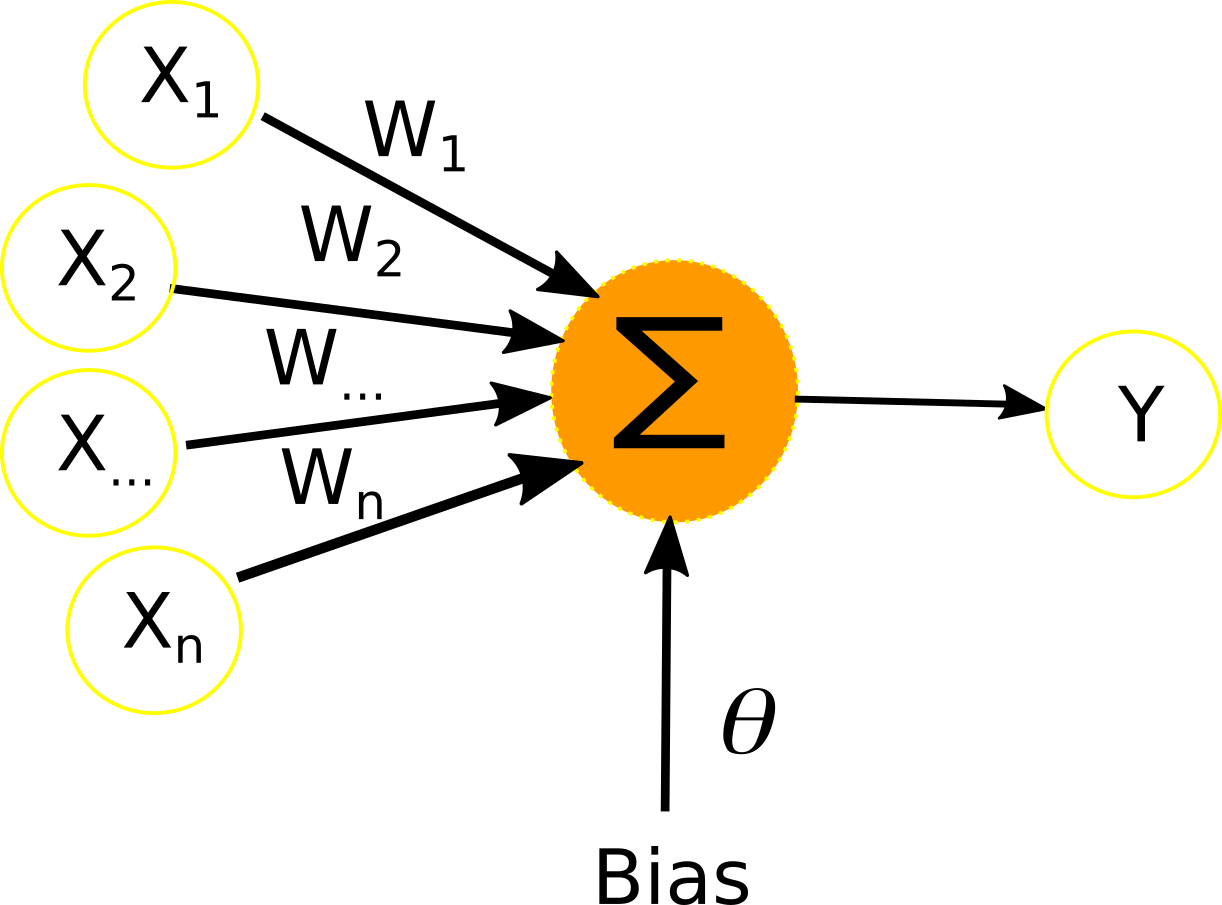
Il possède n entrées (X1 à Xn), auquel seront transmis les données.
À chacune des entrées X est associée un poids W qui servira au calcul de la sortie Y.
Il a ce qu'on appelle couramment une connexion Bias qui est nécessaire à son bon fonctionnement.
Le calcul effectué pour obtenir la sortie Y est le suivant :
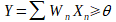
Une fois conçu, il est nécessaire d'
Pour ce faire, nous allons imaginer que nous avons une base de données avec k exemple de différents objets.
Chaque exemple étant composé de n mesure (largeur, poids, hauteur, etc...) de chacun de ces objets.
En sortie, imagine que nous souhaitons savoir si oui ou non l'objet dont nous sommes en présence et un
Je fais référence à un hotdog car récemment j'ai découvert une app assez zarbi pour smartphone qui justement utilise des réseaux de neurones pour savoir si oui ou non l'objet dont on a pris la photo est un hotdog. Elle s'appelle Not Hotdog.
Tu peux la voir en action dans cette vidéo : https://www.youtube.com/watch?v=5HuPd_f5hyM.
Quoi qu'il en soit, revenons à nos moutons.
La sortie est soit zéro, ce n'est pas un hotdog.
Soir un, s'en est bien un. (Dsl : pour le jeu de mots)
L’algorithme qui permet d’entrainer le perceptron est le suivant :
1-Initialisation aléatoire de tous les poids du réseau
Premièrement
2- Choix aléatoire d'un exemple i dans la base B
3- Calcul de la sortie Y pour cet exemple
Pour rappel, Y est égal à la somme des poids * leurs entrées correspondantes.
4- Correction des poids
La correction des poids se fait en utilisant la formule suivante: W_j =W_j +(c - Y) *x_j
Le perceptron multicouche
Le perceptron multicouche est le premier réseau de neurones à avoir trouvé de beaucoup d'application industriels
Il est utilisé pour la résolution de problème de classification supervisée.

L’on peut voir les neurones du perceptron multicouches comme une multitude de perceptron connectés entre eux.
La particularité topologique de ce réseau qui lui donne ses propriétés est que:
Chaque neurone a donc n entrées, n étant le nombre de neurones présent dans la couche précédente.
Chaque neurone a donc une sortie qui est envoyée à tous les neurones de la couche suivante.
À chaque connexion neuronale est associé un poids W, comme pour les entrées du perceptron.
Le calcul de la sortie de chaque neurone présent dans le réseau se fait de la
à ceci près que le résultat est envoyé dans une
cela est nécessaire afin que le réseau de neurones puisse résoudre des problèmes non linéaires complexes.
Il existe différentes fonctions d’activation possible pour un neurone.
La plus populaire à ce jour est
elle est illustrée sur le schéma ci-dessous. Dans le cas ou le résultat est négatif, le neurone retournera zéro, sinon, il retournera le résultat lui-même comme peu le montré le schéma ci-dessous.
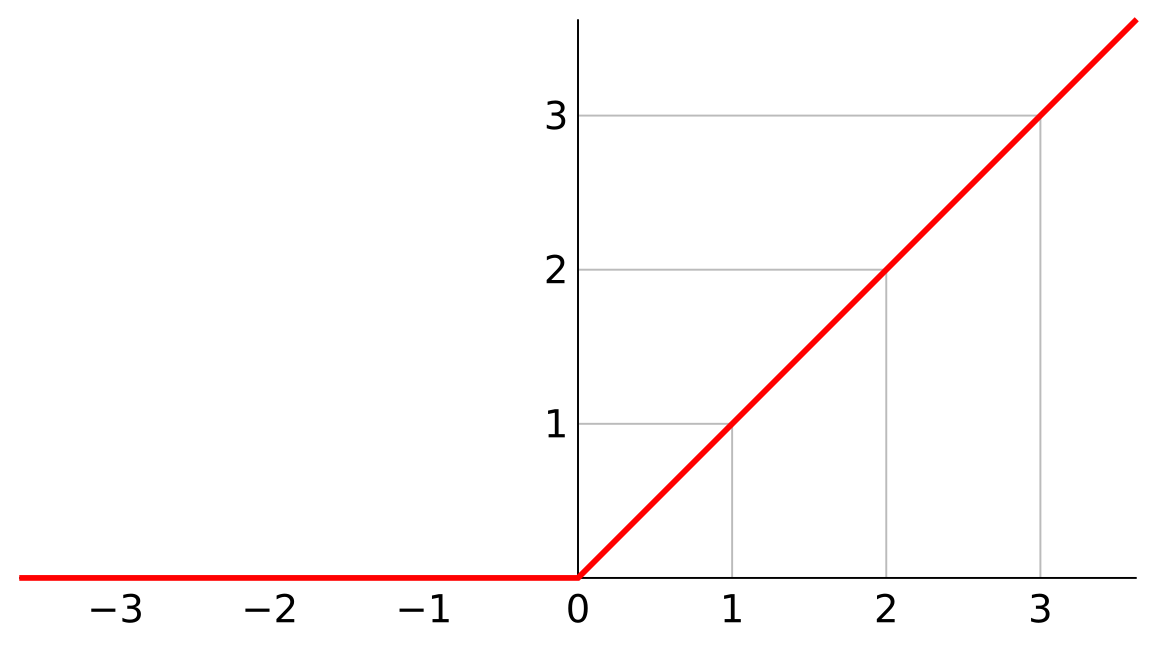
Pour Rectified Linear Unit
D'autres fonctions d'activation existent,
Remarquons qu’il est important que la fonction d’activation soit dérivable, car il sera impossible de calculer l’erreur individuelle de chaque neurone utilisé si la fonction utilisée n’est pas dérivable.
Lors du choix de la fonction d’activation, le programmeur regardera le succès qu’obtient le réseau de neurones dans la tâche qui lui a été attribué, mais aussi le temps d’exécution de la fonction d’activation.
L'algorithme de rétropropagation du gradient permet d'entraîner les réseaux de neurones.
Le fonctionnement des réseaux de neurones à propagation avant est fortement inspiré du fonctionnement du cerveau humain. En effet, tout comme un réseau de neurones à propagation avant, un neurone humain reçoit plusieurs entrées au travers de ses dendrites, modifie cette entrée dans son fonctionnement interne et renvoie un signal de sortie au travers de son axone.
L'algorithme de rétropropagation du gradient construit une fonction qui va produire la sortie désirée selon l'entrée en modifiant les poids du réseau de neurones.
Entrée : Une base constituée B de k exemple
1- Initialisation aléatoire de tous les poids du réseau
2- Choix aléatoire d’un exemple i de la base B et calcul de la sortie Y pour cet exemple avec la formule ( Il s'agit de la propagation avant où foward propagate : en anglais).
A l'image du perceptron le calcul de la sortie de chaque neurones est effectué en faisant la somme des produits des entrées Xn et des poids Wn et en rajoutant le bias 0.Puis cette somme est envoyé dans une fonction de d'activation généralement la fonction sigmoiderror = (expected - output) * transfer_derivative(output)
error = (weight_k * error_j) * transfer_derivative(output)
weight = weight + learning_rate * error * input
4- Une fois la propagation avant terminé, le réseau de neurones à produit une sortie qui doit être corrigé .
la dérivé de la sigmoid est
Les poids de tous les neurones du réseau sont corrigés. Pour cela, pour tous les neurones, en partant du dernier :
En effet, une cellule neuronale humaine reçoit plusieurs signaux d'entrée au travers de ses dendrites et
-AdaGrad
-RMSProp
-Stochastics gradient descent (SGD)
-AdaDelta
-Adam
Un autre exemple de réseau de neurones à propagation avant est le réseau de neurones convolutif.
Il s’agit d’un réseau qui a été inventé par Yann Lecun en 1988 quand il travaillait au laboratoire Bell.
Initialement développé pour la reconnaissance de chèque, le système a connu un réel succès du fait des nombreuses applications possibles telles que la reconnaissance vocale, la reconnaissance d’images, et toute autre tâche nécessitant un travail conséquent de traitement du signal.
Ce réseau utilise des matrices et de convolutions afin de traiter l’information.
Comme on peut le voir sur le schéma ci-dessous, nous avons au départ une image (étape 0), à laquelle sera appliqué n matrice différente (n=8 sur l’image) l’on obtient alors n nouvelles images (étape 1) dont la taille est par la suite réduite (étape 2) avant d’appliqué M matrice aux n images résultante (étape k-1, k étant fixé par l’utilisateur), l’image est ensuite une nouvelle fois recuite (étape k).
Ce processus d’application de matrice puis de réduction est appliqué autant de fois que nécessaire afin d’obtenir le meilleur résultat possible. Cela fait, lors ce que l’image est devenue tellement petite qu’il ne lui reste que peu de pixels (< 100 dépend du choix de l’utilisateur) elle est envoyée a un perceptron mutilcouche qui prédira le résultat.
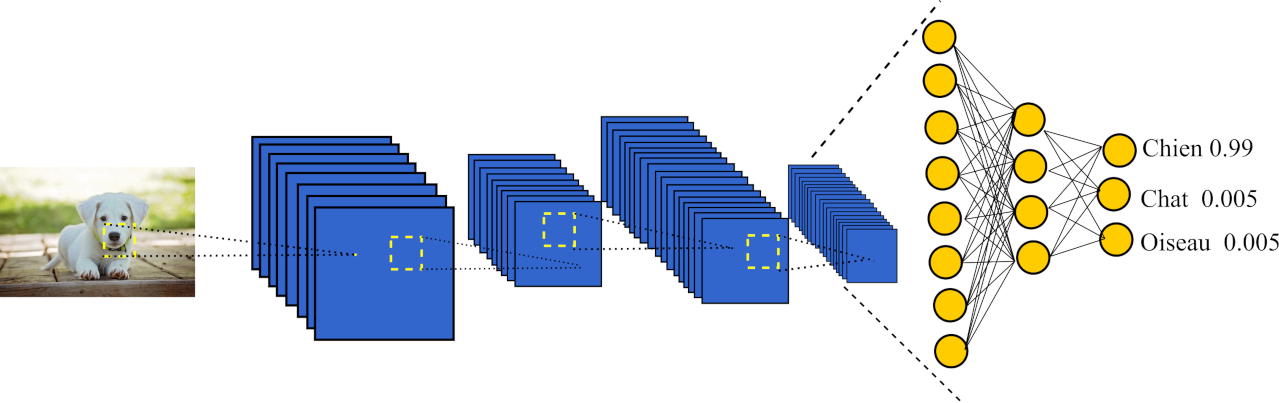
Schéma du réseau convolutionnel de neurones :
Le principe des auto-encodeurs est le suivant : un premier réseau de neurones appelé encodeur va prendre en entrée un vecteur de données de très grande dimension (> 1000) et va transformer ce vecteur en un vecteur de petite dimension (<20) . Par la suite, un second réseau de neurones appelé décodeur va prendre en entrée le vecteur de petite dimension et va reconstituer le vecteur de très grande dimension.
Par exemple, dans le schéma suivant où le fonctionnement d’un auto-encodeur est représenté vous remarquerez qu’au début de la chaine il y a une image de chien, elle est ensuite au milieu de la chaine réduite en un vecteur de caractéristique c’est-à-dire en une suite de valeurs numériques synthétisant l’information comprise à l’intérieur de l’image du chien, c'est une représentation réduite du chien. Puis dans un deuxième temps, un décodeur va se servir de cette représentation réduite pour reconstruire l’image du chien.
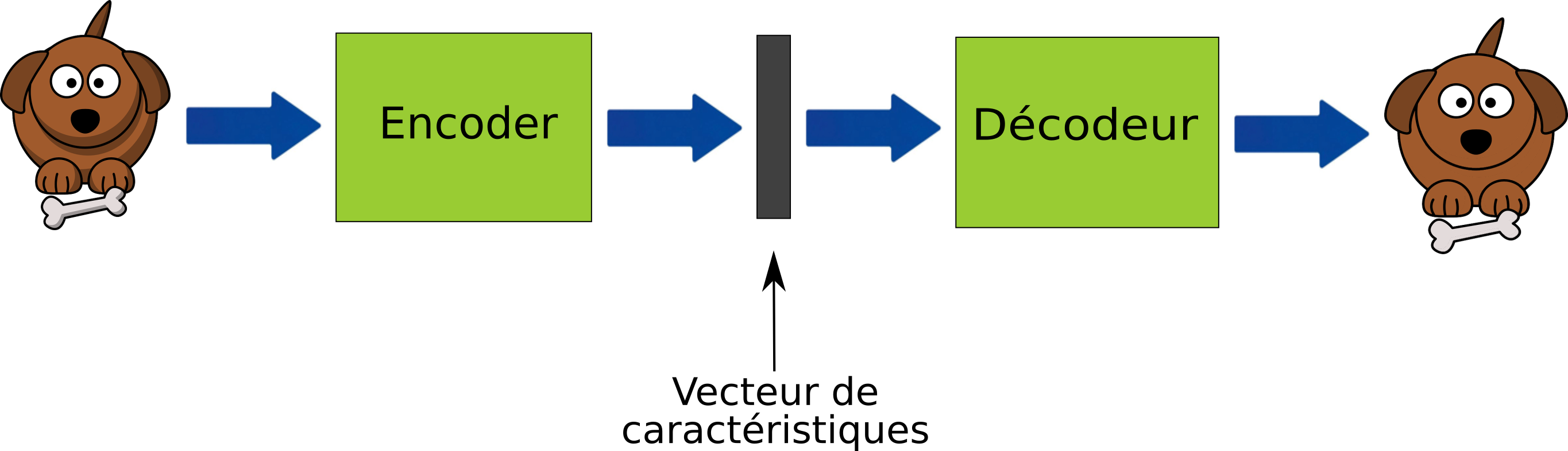
Il est important de préciser qu’entre le vecteur d’entrée et le vecteur de sortie, il y aura une perte d’information, mais celle-ci est généralement acceptable, car très souvent il s’agit du bruit du vecteur d’entrée qui a été retiré.
Le réseau antagoniste génératif est un nouveau type de réseau de neurones inventé en 2014 par Ian Goodfellow ( auteur du livre deep learning consultable légalement via le lien suivant :https://www.deeplearningbook.org ).
Ces réseaux de neurones ont la particularité de pouvoir générer des données inexistantes telles que des images, des vidéos, des musiques, etc.… Par exemple, en 2017, ils ont été utilisés pour générer de fausses vidéos sur internet où l’on voyait l’ancien président américain Barack OBAMA traiter son successeur de « deep shit » où de merde profonde en français. Une autre utilisation détournée a été la génération de vidéo pour adulte avec le visage d’actrice célèbre telle que Scarlett Johannson.

Schéma d'un réseau antagoniste génératif (Phase d'entraînement) :
Les réseaux antagonistes génératifs sont composés de deux blocs principaux : le premier est le générateur et le second est le discriminateur. Chacun de ces blocs est un réseau de neurones à part entière.
Au départ ni le générateur ni le discriminateur ne sont entraînés.
Les deux blocs suivants d’instruction vont être répétés chacun à leur tour:
Block 1 :
Une image dans la base de données image est choisi
elle est envoyée au discriminateur
si l’image est une image réelle et que le discriminateur répond que c’est un fake les poids du discriminateur sont réévalués
Block 2 :
le générateur reçoit en entrée un vecteur de caractéristique
il construit une image
le discriminateur reçoit en entrée l’image construite par le générateur
si le discriminateur répond que c’est une image réelle alors que c’est un fake les poids de celui-ci sont réévalués
sinon si le discriminateur répond que c’est un fake alors ce sont les poids du générateur qui sont réévalués sont ceux du discriminateur. Selon les poids du discriminateur. Via une rétropropagation du gradient.
Le réseau de neurones récurrents se distingue des autres types de réseaux de neurones par sa topologie qui n'a pas d'orientation et notamment que dans ce type de réseau, un neurone peut être typiquement connectés à lui même.
Ce type de réseaux permet la prise en compte du contexte dans le traitement des informations, car ces derniers ont la particularité de se rappeler de l'information passée et donc d'influencer leurs sorties selon celle-ci.
Classiquement, les RNN simples ne peuvent mémoriser que des moments passés dit proche.
C'est pourquoi, généralement l'industrie utilise des réseaux de neurones récurent plus complexe tel que le Long Short Term memory network qui comme son nom l'indique à la capacité de stocker des informations provenant de passé lointain.
Ces derniers seront généralement bidirectionnels, c'est-à-dire que pour les applications le permettant l'on leur donnera des informations passées et des informations futures afin d'améliorer leurs résultats.
Ces réseaux à large « mémoire court-terme » ont notamment révolutionné la reconnaissance de la voix par les machines (Speech Recognition) et la compréhension et la génération de texte (Natural Langage Processing).
[1] https://en.wikipedia.org/wiki/Types_of_artificial_neural_networks
[2] https://en.wikipedia.org/wiki/Recurrent_neural_network
[3] http://www.asimovinstitute.org/neural-network-zoo/
[4] http://people.idsia.ch/~juergen/rnn.html
[5] https://dataanalyticspost.com/Lexique/reseaux-de-neurones-recurrents/
[6] https://fr.wikipedia.org/wiki/R%C3%A9seaux_antagonistes_g%C3%A9n%C3%A9ratifs
[7] https://arxiv.org/pdf/1805.00676.pdf
https://machinelearningmastery.com/implement-backpropagation-algorithm-scratch-python/