L'entraînement des réseau neuronaux à propagation avant se fait en utilisant l'algorithme de rétropropagation du gradient. Ce dernier consiste à soumettre des exemples dont on connait déjà le résultat au réseau de neurones et à utiliser l'écart entre le résultat espéré et le résultat obtenu afin d'améliorer la fonction modéliser par le réseau en modifiant les poids de ce dernier.
Mais qu'en est t'il pour les réseau neuronaux récurrents?
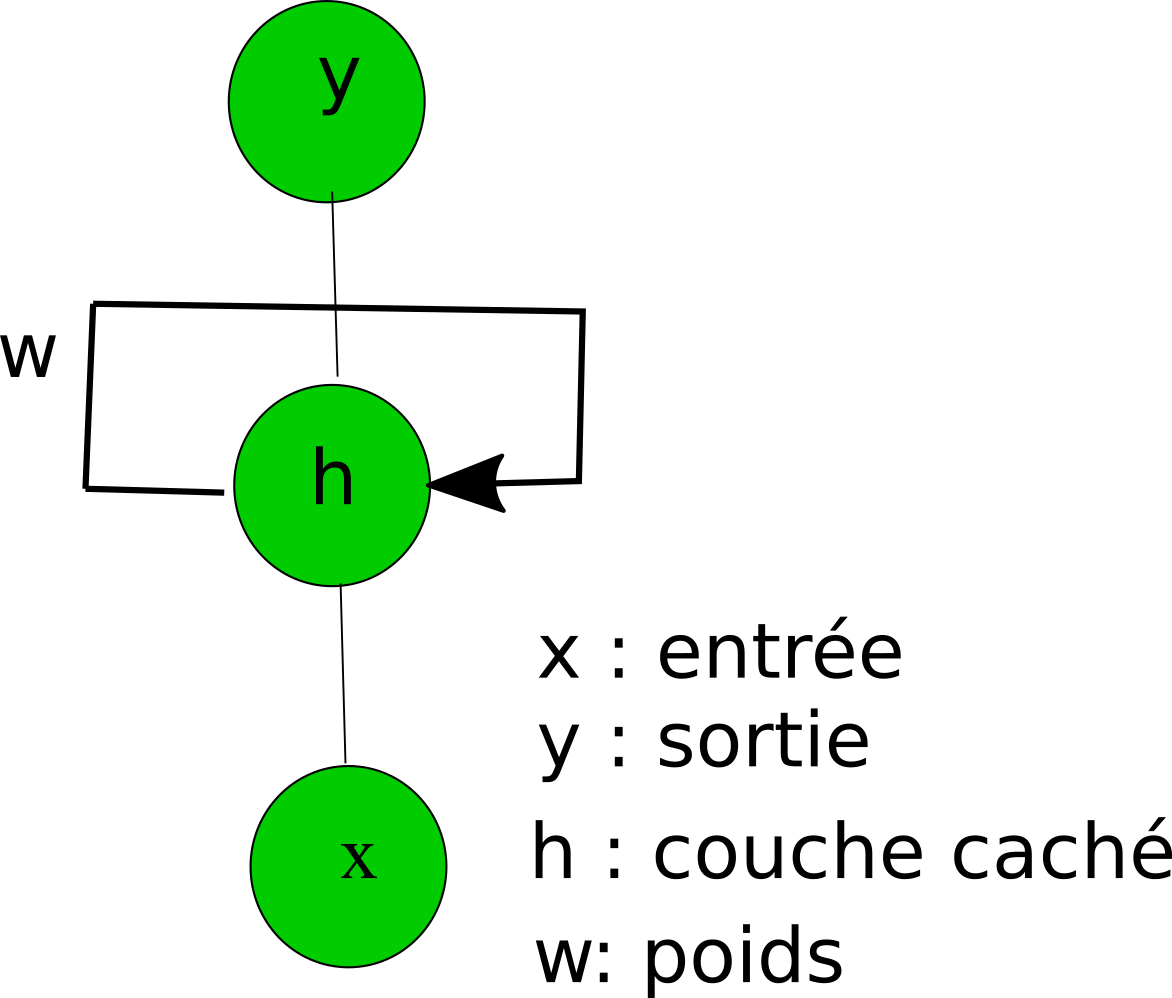
L'entraînement des réseaux neuronaux est nettement moins aisé que celui des réseaux neuronaux classique du fait justement de la présence des connections réccurente.
Comment peut-on corriger des poids récurrent?
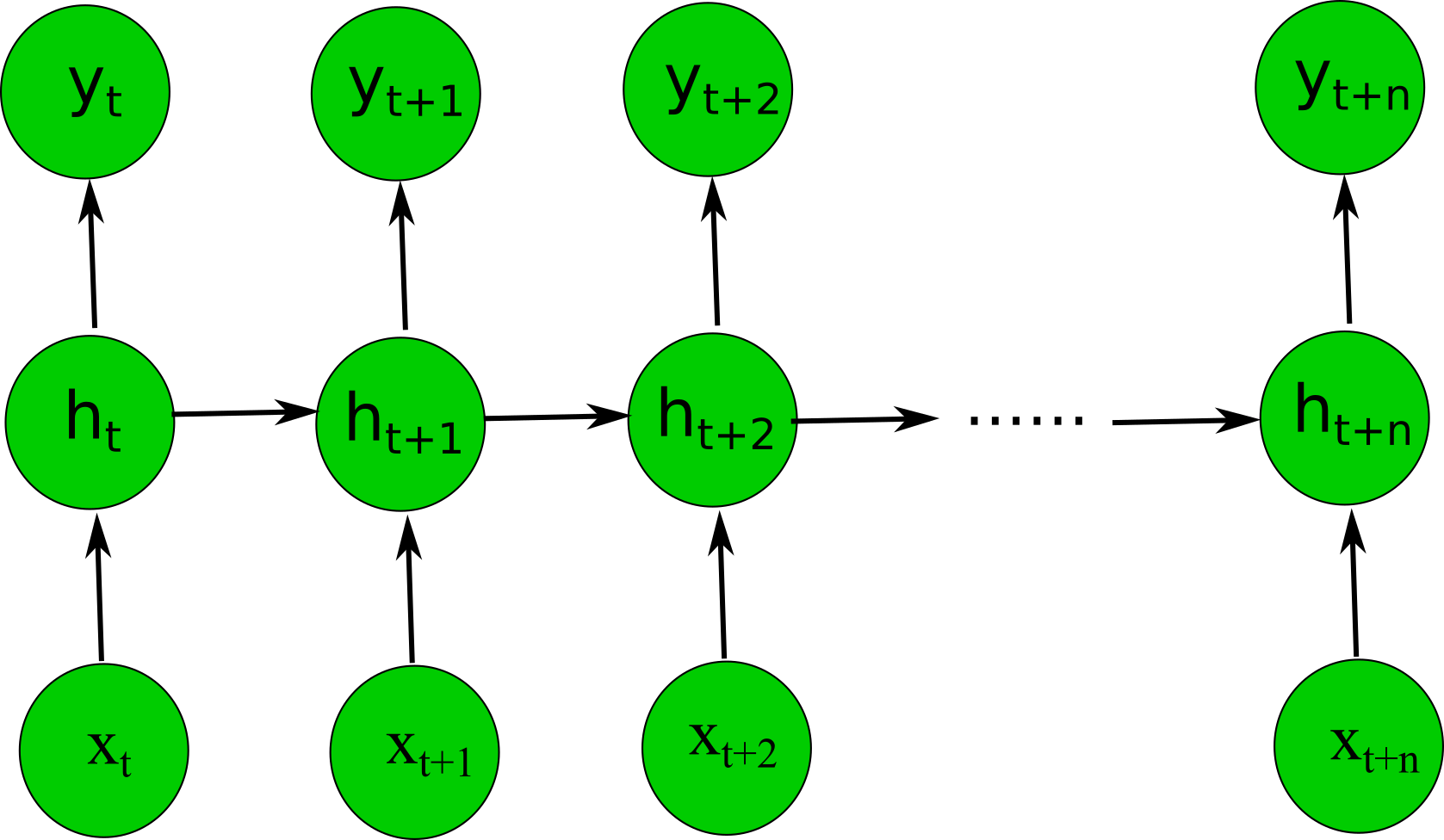
Si on se met à corriger le poids récurrent tels quel, il serait impossible d'entraîner le réseau car cela entraînerait une infinité de gradient. C'est pour cela que lors de son entraînement, le réseau de neurones récurrents sera déroulé selon son évolution au cours du temps pour les séquences reçus en entrée. Le schéma ci-dessous illustre cette propriété.

Ce nouvel algorithme se nomme :la rétropropagation au travers du temps où "Backpropagation through time" (BPTT) en anglais.
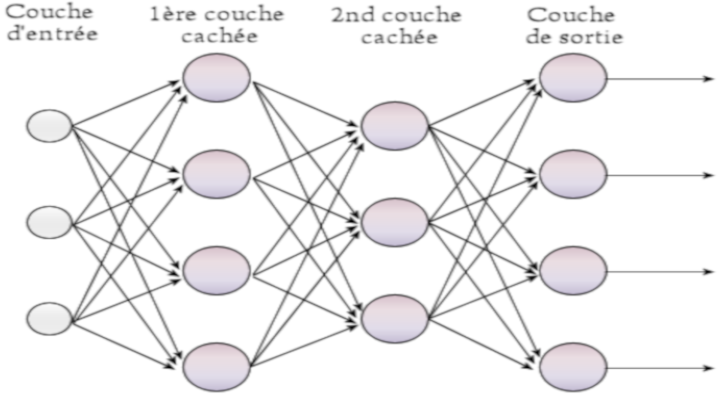
Seulement, vous devez savoir, comme je l'ai dit dans mon article sur le percerptron multi-couches, qu'il ne sert à rien pour un perceptron multi-couches d'avoir plus de 2 couches. En effet, au delà de ce nombre, la performance en classification où en régression selon ce que l'on souhaite faire décroît.
Hors dans le cas d'un réseau neuronale récurrent, quand l'on lui présente une longue séquence lors de son entraînement et que l'on le déroule comme je l'ai dit plus haut, nous obtenons un réseau très profond qui entraîne inévitablement une baisse de la performance du réseau et rends l'algorithme de rétropropagation innefficient pour son entraînement.
Ce problème est couramment connu dans la communauté sous le nom de :exploding or Vanishing gradient.
Exploding or vanishing car lors de l'entraînement soit le gradient devient trop grand (nettement supérieur au poids du réseaux) orientant alors les nouveaux poids générer lors de la rétropropagation du gradients vers des valeurs abérente. Ou encore vanishing "qui disparait" en français (trop petit pour avoir la moindre influence) qui entraîne le réseau dans un entraînement ou il n'avance strictement plus, Les nouveaux poids sont alors les poids de l'itération précédente. L'entraînement n'a aucun effet.
Afin de résoudre cela , la communauté a inventé nombre de méthode tels que les echo state network (ESN), ...., mais à ce jour, la plus populaire et efficace qui à su s'imposé dans l'industrie reste le réseau de neurones LSTM.
Les réseaux de neurones LSTM ont été créé afin de résoudre le Vanishing gradient problem
Forget gate
Input gate
Output Gate
Il existe de nombreux type de réseaux de neurones récurrents tels que :
Pleinement récurrent "fully récurrent"
Réseaux de hopfield Hopfield network
Réseaux récurrent à porte 'Gated reccurent unit' (GRU)
Long Short Term memory network (LSTM)
Machine à état liquide (MEL) - liquid state machine (LSM)
Seulement en pratique seul les LSTM et GRU sont utilisé dans l'industrie.
Traduction automatique de langage
Reconnaissance vocale
Prédiction de séries temporelles (Prix, consommation électrique, marché financier)
Reconnaissance d'action dans les vidéos
Génération de texte
Chatbot
Correction orthographique grammaticale automatique
Reconnaissance de caractère manuscrits
Analyse et classification de texte (emails, commentaire, etc.....)
https://machinelearningmastery.com/crash-course-recurrent-neural-networks-deep-learning/
https://analyticsindiamag.com/overview-of-recurrent-neural-networks-and-their-applications/
https://en.wikipedia.org/wiki/Recurrent_neural_network