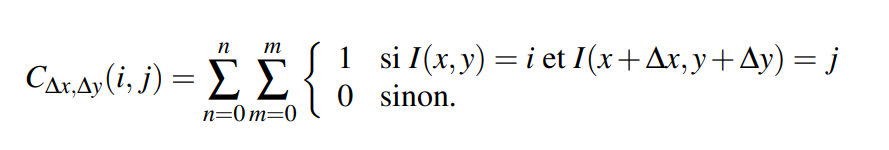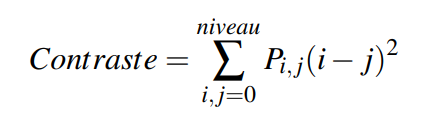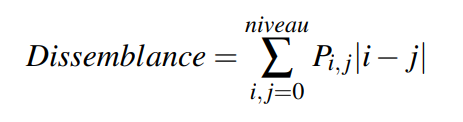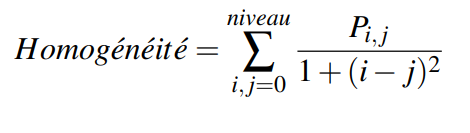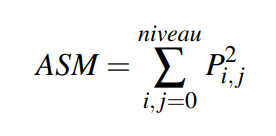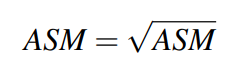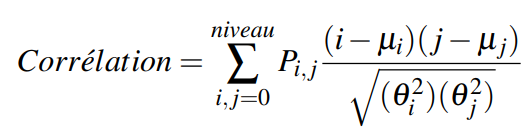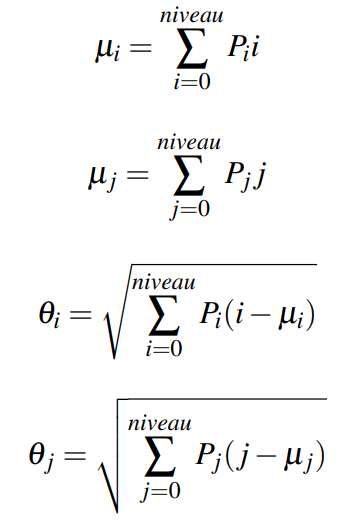OpenCV est la bibliothèque OpenSource de référence en ce qui concerne la vision par ordinateur (ou computer vision en anglais). En 22 ans d'existence, elle a accumulé plus de 2500 algorithmes optimisés issus de la littérature scientifique tels que SIFT, les cascades de Haar, ou encore la transformée de Hough. Elle permet entre autre :
Bien qu'il existe des alternatives telles que MATLAB, Octave ou encore Pandore, OpenCV reste privilégiée par les ingénieurs et scientifiques du monde entier pour l'analyse et le traitement des images.
L'adoption massive d'OpenCV par la communauté de l'analyse et du traitement d'images s'explique par les facteurs suivants :
Au cours de ce tutoriel, nous aborderons les notions suivantes :
Python est actuellement le "langage de référence" ou encore "la lingua franca" pour la pratique du machine learning. C'est un langage simple et puissant qui dispose autour de lui d'une large communauté d'utilisateurs. De ce fait, une large collection d'algorithmes de vision par ordinateur tels que selective-search, les levels-set ,Graph-Cut ou encore les super-pixels sont déjà implémentés en Python. Malgré cela, mon avis sur ce langage demeure mitigé. Autant j'affectionne ce langage, autant je le désaffectionne.
Car Python est un excellent langage de par sa simplicité, sa clarté et le peu de ligne de code qu'il nécessite afin de résoudre un problème. L'utilisation de l'indentation afin de délimiter les conditions et les boucles est une excellente idée. Cependant, en termes de performance, il demeure l'un des pires langages. En effet, l'usage du Python est 76 fois plus énergivore que l'usage du langage C et nécessite 70 plus de temps d'exécution qu'un algorithme implémenté en C.
C'est la raison pour laquelle, mon avis sur le Python reste mitigé.
Aussi, d'expérience, je vous recommande de privilégier Python de manière générale, que ce soit pour apprendre une notion, implémenter ou tester un algorithme. Car ce langage est nettement plus simple. De plus, 500 lignes écrites en python équivalent à 1500 en langage C.
Cependant, dès que le temps d'exécution en Python est trop élevé, pour le problème de vision par ordinateur que vous souhaitez résoudre (ex : Détection et suivi d'objet en temps réel sur du matériel embarqué), je vous recommande d'implémenter les parties les plus gourmandes de votre algorithme dans un second programme C++. Et de faire le programme python communiquer avec le programme C++. Cette communication peut s'effectuer à l'aide de tubes, des sockets ou tout simplement de fichiers écrits directement sur le disque dur.
Si Python n'est pas installé sur votre ordinateur, il vous faut le télécharger depuis la page officielle de téléchargement de python.org puis l'installer.
Page officielle de téléchargement de l'interpréteur Python
Une fois Python installé, le gestionnaire de paquet "pip" est automatiquement installé. Il vous faut donc ouvrir votre terminal de commande puis taper la ligne suivante afin d'installer le package OpenCV de Python.
pip install opencv
Cependant, cette ligne de commande n'a jamais fonctionné pour moi, car je suis sur Windows.
Par conséquent, à chaque fois que je veux installer un package depuis pip je suis obligé de taper "python -m" avant la commande pip officielle.
python -m pip install opencv
Il existe une seconde version d'OpenCV nommée OpenCV Contrib.
En plus de regrouper les algorithmes de la version standard, elle y ajoute d'autres algorithmes relativement plus récents et potentiellement plus performants même si ce n'est pas toujours le cas.
Cependant, les algorithmes d'OpenCV COntrib ne sont pas toujours stables et pleinement testés/validés. Cette version est en quelque sorte un prototype évolutif des prochaines versions d'OpenCV. Ainsi, au fur et à mesure que les algorithmes d'OpenCV Contrib sont validés et gagnent en stabilité et en popularité, ils sont intégrés à la version standard.
On y retrouve par exemple des algorithmes de détection et de reconnaissance de code-barre, de QR code ou encore de texte.
Entre autres, OpenCV Contrib contient les versions CUDA (utilisant la carte graphique) des algorithmes de la version standard. Selon l'application que l'on fait d'OpenCV Contrib et la carte graphique NVIDIA de laquelle l'on dispose, nous pouvons aisément constater des gains en performance de l'ordre de 30 fois (voir plus) comparativement à la version CPU.
La commande pip permettant d'installer OpenCV Contrib est la suivante :
pip install opencv-contrib-python
Pour la suite de ce tutoriel, vous pouvez installer la version d'OpenCV de votre choix. Cependant, nous n'aurons besoin que des fonctions incluses dans la version standard.
Pour utiliser OpenCV, il est nécessaire de charger cette bibliothèque en mémoire en utilisant le mot-clé "import".
import cv2
Afin de charger une image, il faut employer la fonction cv2.imread( nom_image) comme cela :
image =cv2.imread('fleur.png')Pour sauvegarder une image, c'est la fonction imwrite (nom_image, image) qu'il faut utiliser.
cv2.imwrite('fleur.png',gray)Afin d'afficher une image à l'écran, il est nécessaire d'appeler dans un premier temps la fonction namedWindow pour créer une fenêtre graphique.
Puis, il faut utiliser la fonction imshow qui prend pour paramètres le nom de la fenêtre et l'image à afficher.
La fonction waitKey permettra ensuite de mettre la fenêtre en attente d'un événement (clic de souris, touche au clavier, ...).
Pour finir, la fonction destroyAllWindows libérera la mémoire occupée par la fenêtre après que celle-ci ait été fermée.
import cv2
img=cv2.imread ("fleur.png")
cv2.namedWindow('image', cv2.WINDOW_NORMAL)
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Ci-dessous, j'ai mis une petite documentation des fonctions qui ont été utilisées pour afficher l'image.
cv2.namedWindow('image',cv2.WINDOW_NORMAL)cv2.imshow('image',img)cv2.waitKey(0)
cv2.destroyAllWindows()
De manière générale, quand tu vas travailler sur une image, bien souvent,celle-ci sera au format RGB. C'est le pire format qu'il puisse être pour travailler sur une image, car celui-ci est adapté au capteur CMOS que l'on retrouve dans les caméras.
En somme, pour ne pas trop m'attarder là-dessus, je vais t'expliquer comment fonctionne un appareil photo.
Mais pour cela, je vais d'abord t'expliquer le fonctionnement de la rétine humaine, cette petite partie de l'oeil humain qui te permet de voir.
La rétine humaine, si tu l'as un peu étudié sinon je t'invite à lire ce tuto que j'ai écrit, est constitué de 150 millions de capteurs de lumière qui sont de deux types les « bâtonnets » et les « cônes ».
Les bâtonnets sont chargés de la vision scotopique (en noir et blanc) tandis que les cônes sont chargés de la vision photopique (en couleurs). les cônes sont au nombre de 7 millions sur notre rétine et sont divisibles en trois catégories : les cônes de faible, de moyenne et de forte longueur d’onde.Chacune des catégories étant de longueur d'ondes différentes permet de capter une lumière différente c'est pourquoi les cônes de faible, de moyenne et de forte longueur d’onde permettront de capter respectivement la lumière bleue, la verte et le rouge.
Les autres couleurs que l'on peut voir telles que le jaune, le magenta ou encore la couleur du bois sont obtenus par combinaison de ses trois couleurs élémentaires.
Pour le capteur des appareils photo, c'est pareil que pour l'oeil humain il s’agit de milliers de photo-capteurs assemblés ensemble en forme de grille.
Ces photo-capteurs par des processus physiques que je ne peux expliquer puisque ce n'est pas mon domaine d'expertise transforment la lumière en signal électrique. Ce signal continu est par la suite converti en signal numérique qui sera traité par un ordinateur.
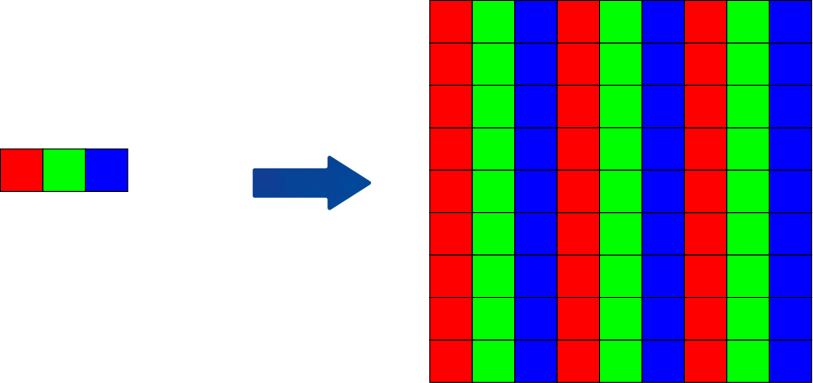
Ce qui a donné naissance à la représentation RGB (Red green blue)

hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
Exemple :
import cv2
img=cv2.imread ("fleur.png")
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
cv2.namedWindow('hsv', cv2.WINDOW_NORMAL)
cv2.imshow('hsv',hsv)
cv2.waitKey(0)
cv2.destroyAllWindows()
Résultat :

Il est possible de transformer une image couleur en niveau de gris avec la ligne de code suivant :
Code
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
Résultat :

La segmentation permet d’isoler les différents objets présents dans une image.
Il existe différentes méthodes de segmentation : la classification, le clustering, les level-set, graph-cut, etc ....
Mais la plus simple est le seuillage, c’est pourquoi je vais te parler uniquement de celle-ci dans cette seconde partie.
Le seuillage est une opération qui permet de transformer une image en niveau de gris en image binaire (noir et blanc),
l'image obtenue est appelée masque binaire.
Le schéma ci-dessous illustre bien ce concept.
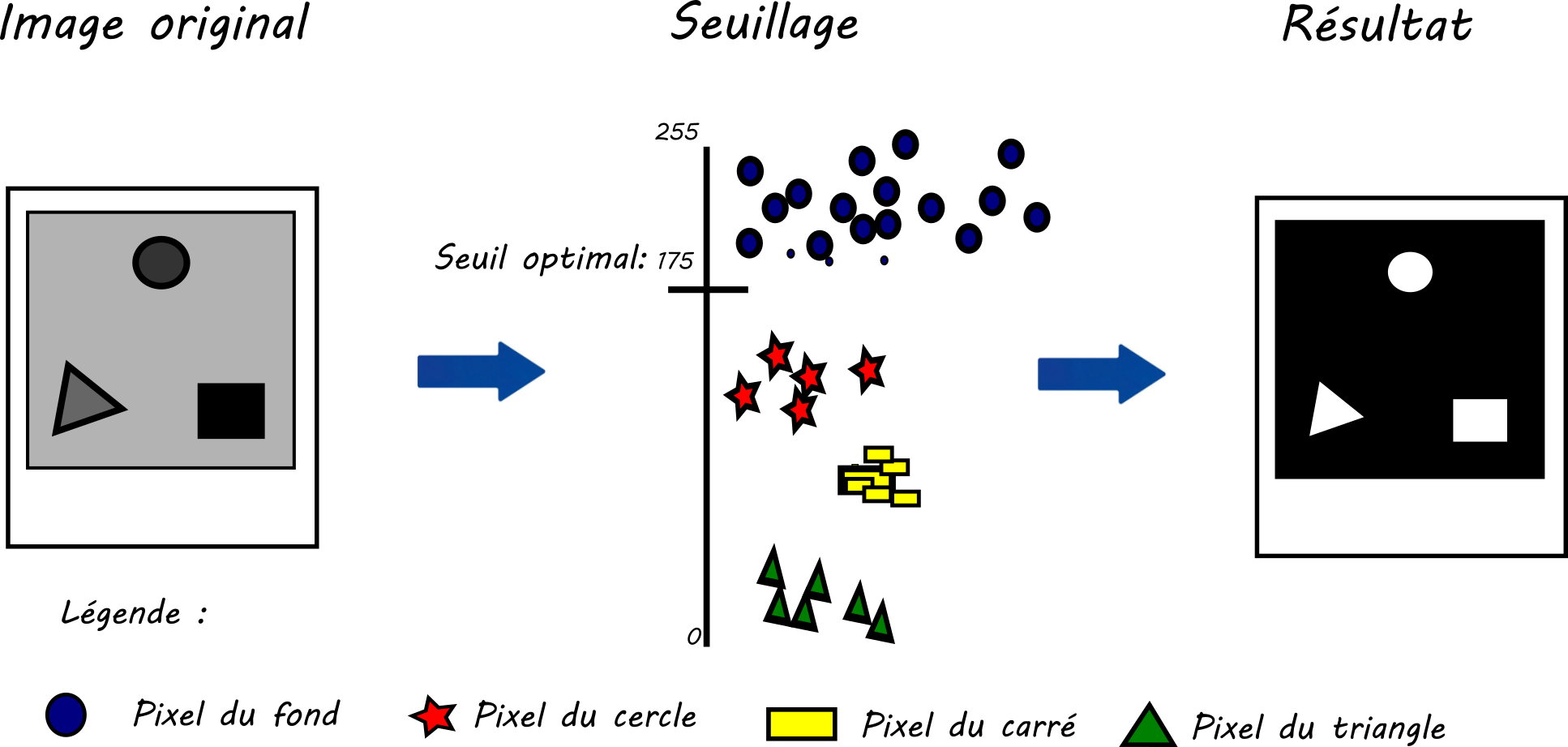
Illustration du seuillage optimal
Il existe 2 méthodes pour seuiller une image, le seuillage manuel et le seuillage automatique.
Sur la l'illustration ci-dessus, trois formes sont présentes dans l’image originale.
Les pixels du rond sont représentés par des étoiles, ceux du carré par des rectangles jaunes, ceux du triangle par des triangles verts et les cercles bleus correspondent au fond.
Dans la figure, nous pouvons remarquer que tous les pixels correspondants du fond (rond bleu) ont une valeur supérieure à 175. Nous en déduisons que le seuil optimal est 175. En faisant cela, nous avons déterminé le seuil optimal manuellement.
Pour utiliser le seuil manuel avec OpenCV, il suffit d’appeler la fonction thresold
comme suit :
ret,th=cv2.threshold(img, seuil,couleur, option)
import cv2
import numpy as np
img=cv2.imread("fleur.png");
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret,th=cv2.threshold(gray,150,255,cv2.THRESH_BINARY)
cv2.namedWindow('image',cv2.WINDOW_NORMAL)
cv2.imshow('image',th)
cv2.waitKey(0)
cv2.destroyAllWindows()

Pour calculer l’histogramme d’une image, il faut faire appel à la fonction calchist :
Code :
hist= cv2.calcHist([img],[i],[256],[0,256])
pip install -U matplotlib
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img=cv.imread ("fleur.png");
#RGB -> HSV.
hsv = cv.cvtColor(img, cv.COLOR_BGR2HSV)
#Déclaration des couleurs des courbes
color = ('r','g','b')
#Déclaration des noms des courbes.
labels = ('h','s','v')
#Pour col allant r à b et pour i allant de 0 au nombre de couleurs
for i,col in enumerate(color):
#Hist prend la valeur de l'histogramme de hsv sur la canal i.
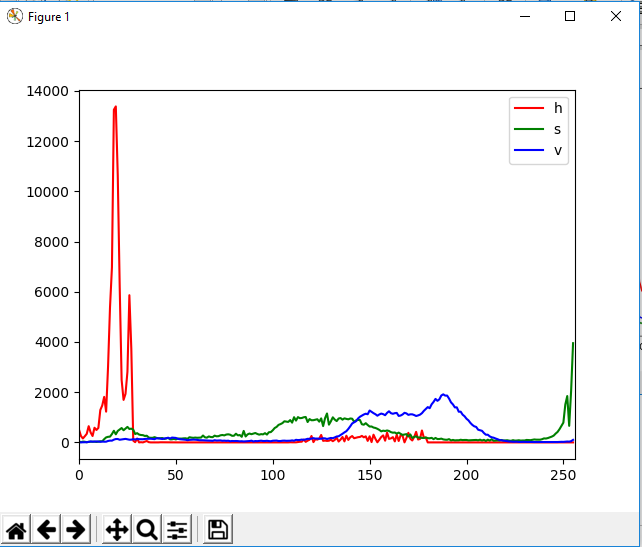
hist = cv.calcHist([hsv],[i],None,[256],[0,256])
# Plot de hist.
plt.plot(hist,color = col,label=labels[i])
plt.xlim([0,256])
#Affichage.
plt.show()
ret2,th2 = cv.threshold(img,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
Exemple : Application de la méthode d’Otsu sur chaque canal de l’image HSV
import cv2 as cv
import numpy as np
img=cv.imread ("fleur.png");
hsv = cv.cvtColor(img, cv.COLOR_BGR2HSV)
h,s,v= cv.split(hsv)
ret_h, th_h = cv.threshold(h,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
ret_s, th_s = cv.threshold(s,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
ret_v, th_v = cv.threshold(s,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
cv.imwrite("th_h.png",th_h)
cv.imwrite("th_s.png",th_s)
cv.imwrite("th_v.png",th_v)



Les opérateurs binaires d’image permettent d’appliquer aux images des opérations binaire logique
telles que le NON, le OU, le ET, mais aussi, le OU exclusif.
cv2.bitwise_not(img)
Le résultat du "ET" est une image dont les pixels sont blancs aux endravec p,q étant les ordres du moment, I(x,y) est la valeur du pixel de l'image à la position (x,y). $\bar{x}$ et $\bar{y}$ sont respectivement les moyennes des abscisses et des ordonnées des pixels appartenant à la région.oits ou les pixels de l’image 1 et de l’image 2 était simultanément blancs. Sa fonction OpenCV est bitwise_and qui prend le paramètre deux images binaires.
cv2.bitwise_and(img1,img2)
Le "ou" passe les pixels en blanc si les pixels de l’image 1 ou de l’image 2 sont blancs. Sa fonction OpenCV est bitwise_or. Elle prend en paramètre deux images binaires.
cv2.bitwise_or(img1,img2)
Le "ou exclusif" passe les pixels en blanc si les pixels de l’image 1 ou de l’image 2 sont blancs, mais pas si les deux sont blanc ensemble. Sa fonction OpenCV est bitwise_xor. Elle prend en paramètre deux images binaires.
cv2.bitwise_xor(img1,img2)
Dans notre cas, nous appliquerons le "ou",car nous voulons une image dans laquelle les pixels des fleurs blanches et des autres fleurs sont allumés.
Autrement dit, nous souhaitons les fleurs présentes sur l’image binaire hue ou sur l’image binaire saturation. Nous utiliserons ensuite la fonction cv2.bitwise_and
pour appliquer le masque binaire obtenu sur l’image fleur.png. Nous obtiendrons ainsi l’image fleur.png privée de son fond. Le code suivant permet de réaliser ces opérations.
Exemple :
import cv2
import numpy as np
img=cv2.imread ("fleur.png");
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
h,s,v= cv2.split(hsv)
ret_h, th_h = cv2.threshold(h,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
ret_s, th_s = cv2.threshold(s,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
#Fusion th_h et th_s
th=cv2.bitwise_or(th_h,th_s)
cv2.imwrite("th.png",th)
Aux lignes 6 et 7 les canaux h et s sont seuillés. Les images binaires résultantes sont th_h et th_s, à la ligne 9 l’image binaire finale th est obtenue en fusionnant et th_h et th_s.

Nous pouvons améliorer ce résultat en retirant les trous à l’intérieur des fleurs blanches. Pour ce faire, nous allons remplir les trous présents dans le masque de l’image.

Cela se fera notamment grâce à la fonction floodfill qui permet de remplir des régions.
cv2.floodfill(im_floodfill,mask,seedPoint,newVal)
cv2.copyMakeBorder(th, top,bottom,left,right,borderType,value)
import cv2
import numpy as np
img=cv2.imread ("fleur.png");
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
h,s,v= cv2.split(hsv)
ret_h, th_h = cv2.threshold(h,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
ret_s, th_s = cv2.threshold(s,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
#Fusion th_h et th_s
th=cv2.bitwise_or(th_h,th_s)
#Ajouts de bord à l'image
bordersize=10
th=cv2.copyMakeBorder(th, top=bordersize, bottom=bordersize, left=bordersize, right=bordersize, borderType= cv2.BORDER_CONSTANT, value=[0,0,0] )
#Remplissage des contours
im_floodfill = th.copy()
h, w = th.shape[:2]
mask = np.zeros((h+2, w+2), np.uint8)
cv2.floodFill(im_floodfill, mask, (0,0), 255)
im_floodfill_inv = cv2.bitwise_not(im_floodfill)
th = th | im_floodfill_inv
#Enlèvement des bord de l'image
th=th[bordersize: len(th)-bordersize,bordersize: len(th[0])-bordersize]
resultat=cv2.bitwise_and(img,img,mask=th)
cv2.imwrite("im_floodfill.png",im_floodfill)
cv2.imwrite("th.png",th)
cv2.imwrite("resultat.png",resultat)
La première partie du code est la même que précédemment. Nous seuillons sur les canaux teinte et saturation, que par la suite nous fusionnons afin d’obtenir le masque binaire de l’image.
Ensuite, nous commençons par ajouter des bords à l’image à la ligne 13, ligne 16, nous créons une image imfloodfill qui contiendra les régions à remplir,le masque est créé à la ligne 19 avec en noir les trous à remplir et en blanc le reste. Nous l’inversons donc à la ligne 20 avant de la fusionner avec le masque de l’image. Nous enlevons les bords que nous avions précédemment mis avant d’appliquer le masque à l’image et d’enregistrer les résultats.
Nous obtenons alors ces trois images avec im_floodfill que j’ai volontairement laissées afin que vous voyiez ce qu’elles contiennent
.



contours, hierarchy = cv2.findContours(thresh,mode,method)
cv2.drawContours(image,contours,contourIdx,couleur, thickness)
x,y,w,h = cv.boundingRect(contours[i])
import cv2import numpy as npimg=cv2.imread ("fleur.png");hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)h,s,v= cv2.split(hsv)ret_h, th_h = cv2.threshold(h,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)ret_s, th_s = cv2.threshold(s,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)#Fusion th_h et th_sth=cv2.bitwise_or(th_h,th_s)#Ajouts de bord à l'imagebordersize=10th=cv2.copyMakeBorder(th, top=bordersize, bottom=bordersize, left=bordersize, right=bordersize, borderType= cv2.BORDER_CONSTANT, value=[0,0,0] )#Remplissage des contoursim_floodfill = th.copy()h, w = th.shape[:2]mask = np.zeros((h+2, w+2), np.uint8)cv2.floodFill(im_floodfill, mask, (0,0), 255)im_floodfill_inv = cv2.bitwise_not(im_floodfill)th = th | im_floodfill_inv#Enlèvement des bord de l'imageth=th[bordersize: len(th)-bordersize,bordersize: len(th[0])-bordersize]resultat=cv2.bitwise_and(img,img,mask=th)cv2.imwrite("im_floodfill.png",im_floodfill)cv2.imwrite("th.png",th)cv2.imwrite("resultat.png",resultat)contours, hierarchy = cv2.findContours(th,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)for i in range (0, len(contours)) :mask_BB_i = np.zeros((len(th),len(th[0])), np.uint8)x,y,w,h = cv2.boundingRect(contours[i])cv2.drawContours(mask_BB_i, contours, i, (255,255,255), -1)BB_i=cv2.bitwise_and(img,img,mask=mask_BB_i)if h >15 and w>15 :BB_i=BB_i[y:y+h,x:x+w]cv2.imwrite("BB_"+str(i)+".png",BB_i)

La caractérisation d’objet est la deuxième étape primordiale d’un logiciel de reconnaissance d’images. Il s’agit de transformer l’imagette de chaque objet en valeurs quantitatives ou qualitatives afin d’obtenir une information traitable par les algorithmes de classification tels que les réseaux de neurones ou encore les arbres de décision. Cette information, se veut être une synthèse d’une ou plusieurs propriétés de l’objet, par exemple l’aire de l’objet est une synthèse de la taille de l’objet.
Il existe quatre grands types d’attributs permettant de décrire un objet à partir des pixels qui le compose :les attributs de région (air, moments, etc ...), de contour (périmètre, les coefficients elliptiques de Fourier, etc.…), de couleur (moyenne,histogramme,etc...) , et de texture (GLCM, filtre de Gabor, etc ….).
Pour des raisons de simplicité, dans ce chapitre, nous travaillerons exclusivement qu'avec les 4 fleurs suivantes :

En analyse d’image, la région d’un objet est définie comme étant l’étendue de pixel qui la compose. La figure ci-dessous illustre cette définition. À côté de chaque fleur, nous pouvons visualiser sa région.
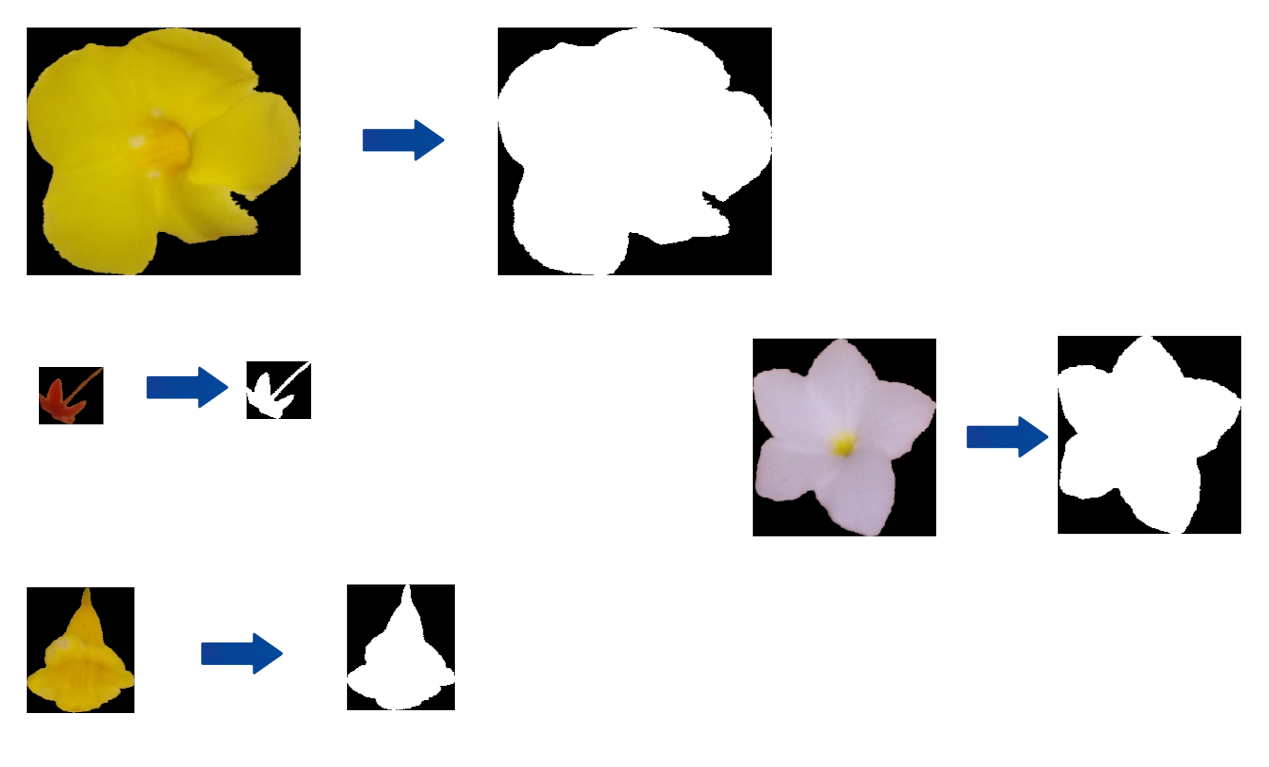
Obtenir l’aire d’une région consiste à compter le nombre de pixels qui la compose. La fonction OpenCV permettant de l’extraire est contourArea(cnt), elle prend en paramètre le contour d’une région et retourne son aire.
Code :
area = cv2.contourArea(cnt)
perimeter = cv2.arcLength(cnt,True)
La circularité est une mesure comprise entre 0 et 1 qui exprime si l’objet est rond. Plus l’objet est rond et plus cette mesure sera proche de 1 et inversement moins l’objet sera rond et moins cette mesure sera proche de 1. La circularité s’obtient via la formule suivante :
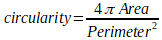
Code :
circularity= 4*area/(perimeter*perimeter)
Il existe d’autres caractéristiques de région basées sur la bounding box de l’objet par exemple la longueur et la hauteur de la bounding box.

Code :
x,y,longueur,hauteur = cv.boundingRect(cnt)
C’est le quotient de la longueur divisé par la hauteur.
Code :
aspect_ratio=w/h
Il s’agit du quotient de l’aire de la région par l’aire de sa bounding box.
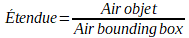
Code :
area = cv.contourArea(cnt)x,y,w,h = cv.boundingRect(cnt)rect_area = w*hextent = float(area)/rect_area
La solidité est le quotient de l’aire d’un objet par l’aire de sa forme convexe.
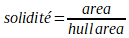
Code :
area = cv.contourArea(cnt)
hull = cv.convexHull(cnt)
hull_area = cv.contourArea(hull)
solidity =float(area)/hull_area
Le diamètre équivalent est le diamètre du cercle ayant la même aire que le contour.
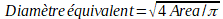
Code :
area = cv.contourArea(cnt)
equi_diameter = np.sqrt(4*area/np.pi)
Exemple :
Dans cet exemple, nous allons calculer l’aire, le périmètre, la circularité, la longueur et la hauteur de la bounding box l’aspect ratio et l’étendue.
Code :
import cv2
import math
fleurs=[] # chargement des images
fleurs.append(cv2.imread ("fleur1.png"));
fleurs.append(cv2.imread ("fleur2.png"));
fleurs.append(cv2.imread ("fleur3.png"));
fleurs.append(cv2.imread ("fleur4.png"));
gray_fleurs=[]
for i in range (0, len(fleurs)): # transformation en niveau de gris
gray_fleurs.append(cv2.cvtColor(fleurs[i], cv2.COLOR_BGR2GRAY))
th_fleurs=[]
for i in range (0, len(fleurs)): # seuillage
ret,th = cv2.threshold(gray_fleurs[i],5,255,cv2.THRESH_BINARY)
th_fleurs.append(th)
contours_fleurs=[] # extraction des contours
for i in range (0, len(fleurs)):
contours, hierarchy = cv2.findContours(th_fleurs[i],cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
contours_fleurs.append(contours)avec p,q étant les ordres du moment, I(x,y) est la valeur du pixel de l'image à la position (x,y). $\bar{x}$ et $\bar{y}$ sont respectivement les moyennes des abscisses et des ordonnées des pixels appartenant à la région.
airs_fleurs=[]
perimetres_fleurs=[]
circularités_fleurs=[]
extent_fleurs=[]
aspect_ratio_fleurs=[]
for i in range (0, len(fleurs)): # extraction des caractéristiques
airs_fleurs.append(cv2.contourArea(contours_fleurs[i][0]))
perimetres_fleurs.append(cv2.arcLength(contours_fleurs[i][0],True))
circularités_fleurs.append(4*math.pi*airs_fleurs[i]/(perimetres_fleurs[i]*perimetres_fleurs[i]))
x,y,w,h = cv2.boundingRect(contours_fleurs[i][0])
extent_fleurs.append(w/h)
aspect_ratio_fleurs.append(airs_fleurs[i]/(w*h))
contours_fleurs.append(contours)
for i in range (0, len(fleurs)): # affichage
print ("fleur",i," : ", " air :", airs_fleurs[i], "perimetre :", perimetres_fleurs[i], "circularité :",
circularités_fleurs[i],"extent :",extent_fleurs[i], "aspect ratio:",aspect_ratio_fleurs[i])
Nous chargeons les images de la ligne 10 à 12, nous passons celle-ci en niveau de gris afin de pouvoir de la ligne 14 à 17 les seuiller. De la ligne 19 à 22, nous extrayons les contours des objets et de la ligne 31 à 35, nous prélevons des objets leurs aires, leurs périmètres, leurs circularités, leurs longueurs, leurs largeurs, leur étendue et leurs aspect ratio.
Résultat :
fleur 0 : aire : 4663.0 perimètre : 685.8376532793045 circularité : 0.12457549745517907 extent : aspect ratio: 0.26860599078341013
fleur 1 : aire : 97072.5 perimètre : 1532.5209821462631 circularité : 0.5193895650343685 extent : aspect ratio: 0.6075575027382256
fleur 2 : aire : 215627.0 perimètre : 2436.507910966873 circularité : 0.45643333292163246 extent : aspect ratio: 0.7069158265715925
fleur 3 : air : 29071.0 perimètre : 869.5777685642242 circularité : 0.4831177331746388 extent : aspect ratio: 0.4716255678131084
Les moments d'une image sont utilisés afin de caractériser la forme d'un objet. Les moments centraux ont la particularité d'être invariants à la translation. Ils sont définis comme suit :
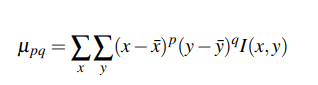
avec p,q étant les ordres du moment, I(x,y) est la valeur du pixel de l'image à la position (x,y). $\bar{x}$ et $\bar{y}$ sont respectivement les moyennes des abscisses et des ordonnées des pixels appartenant à la région.
À partir des moments centraux, il est possible de construire des moments invariants en translation et en échelle en utilisant la formule qui suit :
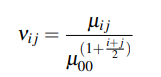
où i et j sont les ordres du moment et $\mu_{ij}$ est le moment central d'ordre i, j, $\mu_{00}$ est le moment central d'ordre zéro.
Un tableau avec les moments centraux suivant: mu20, mu11, mu02, mu30, mu21, mu12, mu03 et les moments invariants à l'échelle suivant : nu20, nu11, nu02, nu30, nu21, nu12, nu03 est retourné par la fonction "moments" d'openCV. Elle prend en paramètre le contour de l'objet traité.
Code :
M=cv2.moments(cnt)
Les moments de Hue se calculent en utilisant les moments invariants à l'échelle. Leurs formules sont les suivantes :
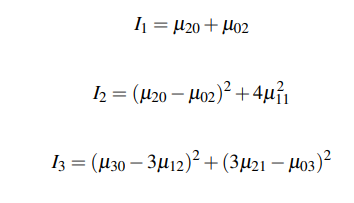
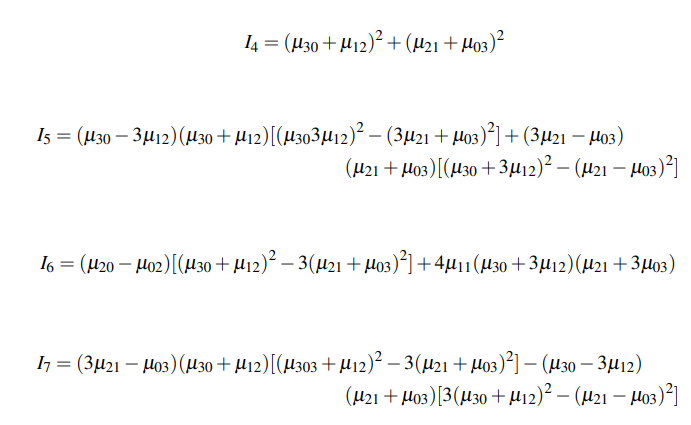

Les matrices de co-occurrences ont été proposées en 1979, par Robert Haralick. Elles sont construites en comptant, dans l'image traitée, le nombre de fois qu'une paire de pixels est présente selon une distance et une direction fixée en paramètre. (équation \ref{eq:GLCM}).