TensorFlow est la librairie de référence quand l'on parle du Deep Learning.
Elle est Leader incontestable du domaine, devant Pytorch ou encore Vectorflow, la nouvelle née de Netflix.
C'est également incontestablement l'une des raisons pour lesquelles le développement de Theano, la bibliothèque de Deep Learning de l'Université de Montréal, a été arrêté (Yoshua Bengio : Theanomajor development would cease after the 1.0 release due to competing offerings by strong industrial players).
Dans sa version 2.0, TensorFlow se montre plus simple que jamais et se veut dès lors accessible à tout un chacun.
Vous le verrez d'ailleurs dans ce tutoriel, si vous connaissiez déjà les précédentes versions de TensorFlow.
Vous verrez à quel point manipuler TensorFlow est devenu simple. J'exagère peut être une peu en disant cela, mais je crois sincèrement que même un enfant de 5 ans qui connaît la programmation python, pourrais utiliser TensorFlow à l'heure actuelle tellement elle s'est simplifiée dans sa version 2.0.
Dans cet article sur TensorFlow 2.0, nous verrons ensemble :
Qu'elle est la méthode la plus simple et rapide pour installer TensorFlow.
Les fonctions usuelles de TensorFlow (créer un Tensor, une couche de réseau neuronal, etc.....)
Comment créer un perceptron multicouche avec TensorFlow
Comment créer un réseau de neurones convolutifs avec TensorFlow
Comment créer un réseau de neurones récurrents avec TensorFlow
Il y a de multiples manières d'installer TensorFlow.
Mais, la plus directe et la plus rapide reste encore de passer par la gestionnaire de paquet officiel de python "pip".
De plus, il existe deux versions de TensorFlow, une qui n'utilise que le processeur et ses optimisations pour effectuer des calculs et une autre qui en plus d'utiliser les ressources processeur, utilise les ressources de la carte graphique pour aller plus vite.
Cette dernière présente l'avantage d'avoir des speed up pouvant aller même au-delà de x100 suivant le type de GPU que tu utilises et selon bien entendu la taille du modèle que tu utilises.
Un petit modèle ira bien plus vite sur le processeur que sur la carte graphique et a contrario un modèle qui prend en entrée de grosses images avec beaucoup de mégas pixels tels que celle qu'on prend avec nos smartphones de nos jours sera littéralement intractable avec le processeur et nécessitera obligatoirement l'appui d'une carte graphique (et une bonne ! Pas comme la Geforce 940 MX sur le PC avec lequel je suis en train d'écrire ce tutoriel).
C'est plus une carte graphique du genre Quadro P5000, Tesla K80 ou encore GTX R2080 (si ça existe) qui permet de traiter ce type d'image.
C'est pourquoi si tu as une carte graphique NVIDIA (car bien sûr il fallait que Google boude AMD, du moins si tu connais une implémentation de TensorFlow pour carte graphique AMD, je te prierais de m'envoyer un mail juste histoire de m'en informer), je vous recommande d'installer la seconde version, celle qui prend en compte le GPU de l'ordinateur.
Mais bon, cela dit, on va voir comment installer les deux versions.
Bien entendu, j'espère que tu as python sur ton ordinateur, car sinon ça va être un peu compliqué sauf si tu veux le faire en C++, il te faudra alors suivre un autre tuto.
La version sans GPU s'installe en tapant la ligne de commande suivante dans votre terminal :
pip install tensorflow
Pour installer installer la version avec GPU, c’est la ligne suivante qu’il faudra taper :
pip install tensorflow-gpu
Mais avant de taper cette ligne dans le terminal, il vous faudra d’abord télécharger et installer les programmes suivant :
TensorRT (Optionnel)
Afin d’installer les prérequis nécessaires à tensorflow pour pouvoir utiliser la carte graphique.
J'imagine que la question qui te brûle les lèvres à cet instant même est comment construire un réseau de neurones c'est pour ça que l'on va directement rentrer dans le steak avec les 5 étapes à suivre pour construire un modèle avec TensorFlow ensuite nous enchaînerons avec la construction d'un perceptron multicouche et enfin nous finirons avec la construction d'un réseau de neurones convolutifs, le modèle particulièrement utilisé pour la classification d'image et qui à ce jour reste indétrônable dans quasiment toutes les compétitions de vision par ordinateur.
Voici les 5 étapes de construction d'un réseau de neurones :
Maintenant que vous avez téléchargé TensorFlow, nous allons voir les 5 étapes basiques dans l'élaboration de tout modèle.
1 Mise en place l'architecture du réseau ( en bref on dit combien de couches il a et de quel type est chacune des couches)
2 Choix d'une méthode d'entraînement et compilation du modèle ( ici on choisit, l'algorithme d'entrainement et la métrique dévaluation du modèle)
3 Entraînement du modèle (je ne vois pas comment être plus clair que cela )
4 Évaluer le modèle (ici aussi)
5 Test du modèle ( Prédiction sur une base d'exemples inconnus)
Nous commençons dès à présent avec la mise en place de l'architecture du modèle.
Avec TensorFlow 2.0 vient l'inclusion de Keras dans le dépôt officiel de cette TensorFlow. C'est notamment la raison comme je l'ai dit plus haut pour laquelle même une enfant de 5 ans qui connaît le langage python (J'exagère peut-être un peu en disant ça) pourrait manipuler TensorFlow avec aisance. Tellement l'inclusion de Keras a simplifié les choses. C'est d'ailleurs la raison pour laquelle, nous nous en servirons dans toutes la suite, mais également la raison pour laquelle les développeurs de Google et de Keras recommandent l'abandon de Keras, mais également des anciens modules de TensorFlow permettant la création de Réseau de neurones au profit du module tensorflow.keras que j'appellerais tf.keras dans la suite par souci de simplification.
Pour construire un réseau de neurones,il est nécessaire d'utiliser la classe sequential de tf.keras. Cette classe représentera en machine le réseau, c'est à cette dernière qu'on ajoutera des couches, mais qu'on entrainera et testera également. La création d'un modèle se fait comme suit :
# Importation de TensorFlowimport tensorflow as tf#Création du modèlemodel=tf.keras.Sequential()
Simple, Non?
Maintenant que nous avons construit le modèle, nous allons lui rajouter les couches.
Disclaimer : Dans cet article, je pars du point de vue que vous savez d'hors et déjà ce qu'est un réseau de neurones et qu'est-ce qu'une couche. Si ce n'est pas le cas, je vous invite à vous reporter à mon article sur les réseaux de neurones. Dès lors nous pouvons continuer plus en profondeur.
Pour ajouter une couche à un modèle, il faut utiliser le module layer de tf.keras et notamment les classes qui compose ce module.
Il faut tout d'abord définir une couche d'entrée, c'est comme cela qu'il est possible de le faire :
layer=tf.keras.layers.Input(shape=[4], name='input')
Le constructeur de layers.Input prend principalement en paramètre la taille de la couche d'entrée. Ici l'on en mettant shape=[4] , je déclare que l'entrée du réseau est un vecteur de caractéristique de dimension 4. Si j'avais voulu que ce soit une image en niveau de gris j'aurais plutôt mis shape=[256,256,1] pour indiquer une image de 256 px de hauteur et de 256 px de largeur et 1 canal qui signifie niveau de gris. Pour une image couleur en entrée par exemple ça aurait été shape=[256,256,1] 3 étant le nombre de canaux.
Il faut ensuite se servir de la fonction add du modèle que l'on a créé précédemment pour ajouter cette couche
#Ajout d'une couche d'entrée avec 4 entréemodel.add(layer)
Mais de manière général, la couche est créée puis directement passé au modèle.
#Ajout d'une couche d'entrée avec 4 entréemodel.add(tf.keras.layers.Input(shape=[4], name='input_image'))
Pour les couches cachées, les choses se corsent un peu, car c'est nettement plus technique. À l'image des réseaux de neurones pour lesquels il y a différent type de couche, TensorFlow inclut différents types couches cachés.(Dense, Conv1D, Conv2D...). Je vais tout d'abord vous présenter la couche Dense qui est une couche de neurones pleinement connectée (tous les neurones de cette couche sont connectés à tous les neurones de la couche qui suit) typiquement utilisée dans la conception du perceptron multi-couche.
Cela se fait en utilisant la classe tf.keras.layers.Dense
#Ajout d'une couche cachée de 18 neurones pleinement connectémodel.add(tf.keras.layers.Dense(18, activation='relu'))
Le constructeur de cette dernière prend principalement 2 paramètres, le premier est le nombre de neurones de la couche, le second est la fonction d'activation "relu". Il est possible de ne pas donner en paramètre la fonction d'activation, mais si c'est le cas TensorFlow utilisera par défaut la fonction d'activation linéaire a(x)=x comme il est précisé dans la documentation officielle.
Pour finir, nous allons créer la couche de sortie. Typiquement ce sera une couche Dense si vous êtes dans un problème de classification, ou de régression. La fonction d'activation sera softmax si vous êtes dans le cas d'un problème de classification, dans le cas d'un problème de régression, il est possible de ne pas la préciser et donc d'utiliser celle prévu par défaut (fonction linéaire).
#Ajout d'une couche de sortiemodel.add(tf.keras.layers.Dense(3, activation='softmax'))
Pour conclure, l'ensemble du code que nous avons implémenté jusqu'ici :
# Importation de TensorFlowimport tensorflow as tf#Création du modèlemodel=tf.keras.Sequential()#Ajout d'une couche d'entrée avec 4 entréemodel.add(tf.keras.layers.Input(shape=[4], name='input_image'))#Ajout d'une couche cachée dense de 18 neuronesmodel.add(tf.keras.layers.Dense(18, activation='relu'))#Ajout d'une couche de sortiemodel.add(tf.keras.layers.Dense(3, activation='softmax'))
Une fois que vous avez fini de créer votre modèle, vous pouvez afficher son architecture en vous servant de la fonction summary.
model.summary()
Exemple :
# Importation de TensorFlowimport tensorflow as tf#Création du modèlemodel=tf.keras.Sequential()#Ajout d'une couche d'entrée avec 4 entréemodel.add(tf.keras.layers.Input(shape=[4], name='input_image'))#Ajout d'une couche cachée dense de 18 neuronesmodel.add(tf.keras.layers.Dense(18, activation='relu'))#Ajout d'une couche de sortiemodel.add(tf.keras.layers.Dense(3, activation='softmax'))#Affichage de l'architecture du modèlemodel.summary()
Résultat :
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 18) 90
_________________________________________________________________
dense_1 (Dense) (None, 3) 57
=================================================================
Total params: 147
Trainable params: 147
Non-trainable params: 0
_________________________________________________________________
Le résumé "summary" du modèle nous donne des informations sur le modèle, tels que le nombre de couche, le type de couche, le nombre de neurones par couche, la dimensions de chaque couche et le nombre de paramètres à entrainer. Dans ce cas-ci, Nous pouvons constater que le modèle créer à 147 paramètres a entraîner.
Maintenant que l'architecture du modèle est créée, il ne reste plus qu'à définir comment ce dernier sera entraîné. Cela se fait à l'aide de la fonction compile. Pour compiler le modèle, trois paramètres doivent être fournis dans cette fonction, la méthode d'entraînement « optimizer », la métrique d'évaluation « metrics », et la fonction de coût « loss ». De nombreux optimizer. Il n'est pas nécessaire de tous les connaître, les plus populaires son Stochastic gradient descent « sgd », adam, adagrad, rmsprop.
Exemple :
#Compilation du modèle
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy',metrics=['accuracy'])
Selon le problème traité, la métrique et la fonction de coût utilisées seront amenées à variés.
Problème de classification binaire :
fonction de coût : binary_crossentropy, métrique accuracy
Problème de classification :
fonction de coût : categorical_crossentropy, métrique accuracy
Problème de régréssion :
fonction de coût : mse (mean squarred error), métrique mae (mean average error),mse (mean squarred error)
L'entraînement du modèle se fait en appelant la fonction fit.
model.fit(X_train, y_train, epochs=500)
Elle prend principalement pour paramètre les exemples d'apprentissage, leurs classes et le nombre d'époque. Nous allons tout de suite mettre en pratique tout ce que l'on a appris avec un exemple.
Le modèle est évalué en 2 temps, dans une premier temps, il est évaluer sur une base nommée base de validation c'est cette base qui s'assurera que le modèle n'a pas surappris.
#Évaluation du réseau
loss, accuracy = model.evaluate(X_test,y_test)
print("Accuracy", accuracy)
Enfin pour prédire un ou des exemples, il faut utiliser la fonction prédict comme ci-dessous.
exemple = [6.3,2.8,5.1,1.5]
prediction = model.predict([exemple])
Dans cette deuxième partie, nous allons utiliser toutes les notions que l'on a vu dans la première partie afin de construire un réseau de neurones pour classer les fleurs du célèbre jeu de données Iris.
Donc, je vais expliquer rapidement en quoi consiste le jeu de données Iris.csv.
Tu peut le télécharger via ce lien.
Il s'agit d'un jeu de données constitué à partir de mesures prélevées de fleurs appartenant à 3 espèces différentes (Iris Setosa, Iris versicolore et Iris Virginia).
Il est constitué au total de 150 exemples avec 50 exemples pour chaque espèce.
Les quatre mesures qui ont été prélevées sont : la longueur de sépale, la largeur de sépale, la longueur de pétale et la largeur de pétale.
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
6.0,2.9,4.5,1.5,Iris-versicolor
5.7,2.6,3.5,1.0,Iris-versicolor
7.9,3.8,6.4,2.0,Iris-virginica
6.4,2.8,5.6,2.2,Iris-virginicaPour charger en mémoire le jeu de données, il nous faudra utiliser la librairie python csv.
Il s'agit d'une librairie qui permet de lire, de modifier et d'écrire des fichiers csv simplement.
Elle est par défault installée avec python.
Dans un fichier csv, la dernière collonne indique généralement la classe et toutes les colonne avant indique les attributs.
from __future__ import absolute_import, division, print_function, unicode_literals
#Chargement du fichier iris.csv
import csv
iris_data=[]
iris_classe=[]
with open('iris.csv') as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
for row in csv_reader:
iris_data.append([float(row[0]),float(row[1]),float(row[2]),float(row[3])])
iris_classe.append(row[4])
pip install -U scikit-learn
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import preprocessing
import numpy as np
import tensorflow as tf
#Encodage des classes afin qu'elles soit utilisable par le réseau de neurones
le = preprocessing.LabelEncoder()
#[Iris-virginica,Iris-versicolor,Iris-setosa]=>[1,2,3]
iris_classe=le.fit_transform(iris_classe)
#[1,2,3]=>[[1,0,0],[0,1,0],[0,0,1]]
iris_classe=tf.keras.utils.to_categorical(iris_classe,num_classes=3,dtype='float32')
#Split de la base principale en une base d'app et de test
X_train, X_test, y_train, y_test = train_test_split( iris_data, iris_classe, test_size=0.33, random_state=42)
#Opération centrer-réduire les données
scaler = preprocessing.StandardScaler().fit(X_train)
X_train=scaler.transform(X_train)
X_test=scaler.transform(X_test)
#Déclaration du réseau de neurones, 4 entrées, 1 couche cachée de 10 neurones, 3 sortie possibles
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation='relu', input_shape=(4,)),
tf.keras.layers.Dense(3, activation='softmax')
])
#Compilation du modèle
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
#Entrainement du réseau
model.fit(X_train, y_train, batch_size=32, epochs=500)
#Évaluation du réseau
loss, accuracy = model.evaluate(X_test,y_test)
print("Accuracy", accuracy)
Accuracy 0.98
98 % des fleurs dans le jeu de test ont été reconnues.
C'est à toi, d'identifier sur le taux de reconnaissance qu'obtient le réseau que tu as obtenu est suffisement bon pour l'application que tu cherche à en faire.
Certaine fois un taux de 95% sera tout à fait excellent si l'application faite ne nécessite pas plus.
Par contre si des vies humaines sont en jeu, comme par exemple dans le cas de la détection de cancer, on peut rapidement comprendre que 95 % n'est pas sufisant.
Cela signifierais que 5% des cancer sont oublié et que par conséquent 5 personnes sur 100 en meure.
Pour finir voici, le code complet :
from __future__ import absolute_import, division, print_function, unicode_literals
#Chargement du fichier iris.csv
import csv
iris_data=[]
iris_classe=[]
with open('iris.csv') as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
for row in csv_reader:
iris_data.append([float(row[0]),float(row[1]),float(row[2]),float(row[3])])
iris_classe.append(row[4])
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import preprocessing
import numpy as np
import tensorflow as tf
#Encodage des classes afin qu'elles soit utilisable par le réseau de neurones
le = preprocessing.LabelEncoder()
#[Iris-virginica,Iris-versicolor,Iris-setosa]=>[1,2,3]
iris_classe=le.fit_transform(iris_classe)
#[1,2,3]=>[[1,0,0],[0,1,0],[0,0,1]]
iris_classe=tf.keras.utils.to_categorical(iris_classe,num_classes=3,dtype='float32')
#Split de la base principale en une base d'app et de test
X_train, X_test, y_train, y_test = train_test_split( iris_data, iris_classe, test_size=0.33, random_state=42)
#Opération centrer-réduire les données
scaler = preprocessing.StandardScaler().fit(X_train)
X_train=scaler.transform(X_train)
X_test=scaler.transform(X_test)
#Déclaration du réseau de neurones, 4 entrées, 1 couche cachée de 10 neurones, 3 sortie possibles
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation='relu', input_shape=(4,)),
tf.keras.layers.Dense(3, activation='softmax')
])
#Compilation du modèle
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
#Entrainement du réseau
model.fit(X_train, y_train, batch_size=32, epochs=500)
#Évaluation du réseau
loss, accuracy = model.evaluate(X_test,y_test)
print("Accuracy", accuracy)
Dans cet seconde partie de l'article, nous allons voir comment implémenter un réseau convolutionnel de neurones en python avec TensorFlow.
Si tu ne sais pas c'est quoi un réseau de neurones convolutionnel, je vais rapidement te l'expliquer.
Dans l'exemple que je t'ai montré précedemment, avec le jeu de données Iris.csv, nous avions quatre caratéristique qui permettait de discriminer les exemple de fleur.
Il s'agit de la longeur de sépale, de la largeur de sépale, de la longueur de pétale, et de la largeur de pétale.
Seulement, tu t'immagine bien que dans la réalité, on n'as pas toute ces mesures la toute cuite sur un plateau.
Il faut soi :
Prendre la fleur et la mesurer manuellement avec une règle. Ce processus peut être particulièrement long surtout si il y a des millier de fleur à analyser.
Prendre une photo de chaque fleur et construire une programme d'analyse d'image qui permettra de prélever ces quatre mesure.
En clair il faut être expérimenter en traitement d'images.
Cela n'arrange donc finalement que les expert en traitement d'images.
Pour palier cela, en 1988 Yann Lecun au laboratoire Bell invente les réseaux de neurones convolutifs.
La particularité de ces réseau est que contrairement au réseau classique tel que le perceptron multi-couche qui ont besoin des données prémaché pour pouvoir effectuer le job,
Ces réseau n'ont juste besoin que de l'image brute.
Ainsi, même quelqu'un n'y connaissant rien au traitement d'images, s'il a suffisement d'images des fleurs, il sera en mesure de construire un programme capeble de les discriminer, sans forcer comme normalement il devrait pour extraire les différentes mesures de fleurs.
Ci dessous tu peux voir le schéma d'un réseau de neurones convolutif.
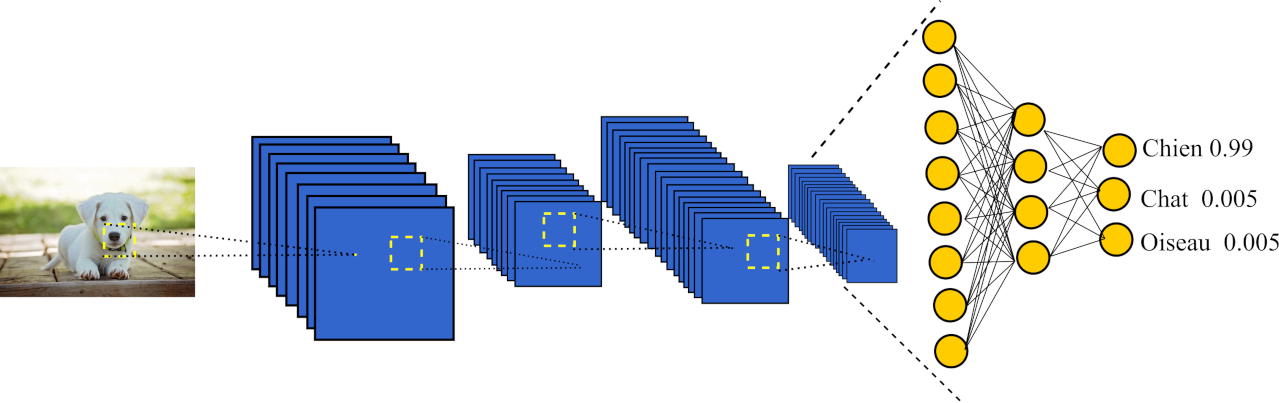
Schéma du réseau convolutionnel de neurones :
Comme tu peux le voir, en entrée de ce réseaux comme je te lai dit précédemment, on y envoi une image.
Cette image, va ensuite être modifiée plusieurs fois et donné naissance à différente images sous l'action des filtres du réseau de neurones.
Chacune des images seront réduite à la suite d'une opération de pooling. Cette dernière, à pour but de résumer l'information se trouvant dans l'image.
Les deux étapes que je viens de citer sont nommer respectivement "convolution" et "pooling".
Elle sont répéter autant de fois que le concepteur du réseau le souhaite.
En effet, pour le faire, ce dernier n'a juste qu'a ajouter au réseau une couche de convolution, à la suite de laquelle, il ajoutera une couche de pooling.
De nouvelle images sont alors générée et la taille de celle-ci est alors réduites jusqu'a ce quelle soit écrasé par une couche flatten comme je le montrerais plus bas et envoyé en entrée d'un percetron multi-couches.
Tu l'as donc probablement compris, le but de toute ces opération de convolution et de pooling est de prémacher le boulot, afin de pouvoir envoyé les informations extraites de l'image à un perceptron multi-couches.
Exactement comme l'aurait fait un ingénieur en traitement d'images traditionnel, mise à part que cette fois ci c'est totalement automatique.
Moins de boulot, moins de mal de tête donc. C'est tout bénèf.
J'imagine que la maintenant il y a probablement un question qui doit te grater la tête, car tout ce que je te dis est bien beau mais pas forcément logique.
Cette étapes de convolution, comment fait telle pour savoir comme modifier les images envoyé en entrée pour finalement extraire les informations contenu dans l'image.
Alors moi je te réponds alors "Élémentaire mon cher Watson",
Les filtre sont automatiquement déterminé grâce à l'algorithme de rétropropagation du gradient qui sert à entraîner le réseau.
En effet, ce réseau peut être utilisé pour traité tout type de signaux, ainsi certain seront utilisé pour la reconnaissance vocal.
Nous allons utilisé ce réseau de neurones pour reconnaître les caractères du jeu de données Mnist.
Je t'explique donc brièvement MNIST :
Mnist est un jeu de données contenant des numéros (compris entre 0 et 9) écrit à la main. Sur l'image ci dessous tu peux voir un extrait de ce jeu de données. Le jeu de données est déjà séparé en une base d'apprentissage qui contient 60 000 exemples et une base de test qui contient 10 000 exemples.
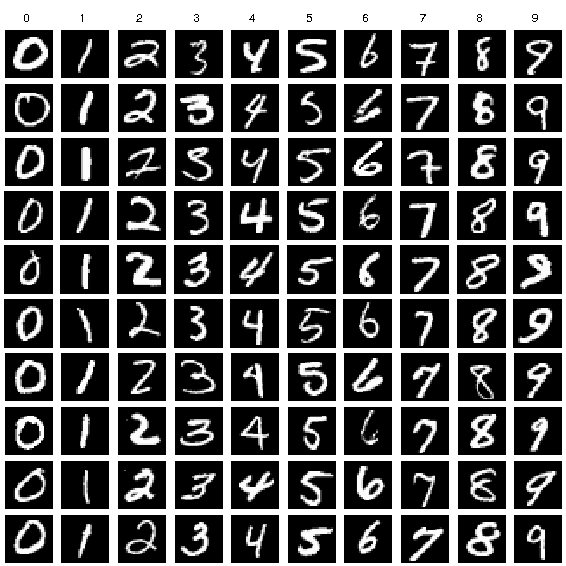
#Fonction de chargement du fichier train.csv contenant les caractère de mnist
def load_dataset():
a=0
train_images=[]
train_labels=[]
test_images=[]
test_labels=[]
#Initialisation de random
random.seed(30)
#Ouverture et lecture de train.csv
with open('train.csv', 'r') as csvfile:
myreader = csv.reader(csvfile, delimiter=',', quotechar='|')
i=0
for row in myreader:
if i!=0:
image_lbp=np.array(row[1:]).astype(np.float)
choix=random.randint(0,3)
#Un exemple sur 3 va dans la base de test le reste dans la base d'apprentissage
if choix==1 :
test_images.append(image_lbp)
test_labels.append(int(row[0]))
else :
train_images.append(image_lbp)
train_labels.append(int(row[0]))
i+=1
return train_images,train_labels,test_images,test_labels
Comme je l'ai expliqué précedement, un réseau de neurones convolutionel n'est ni plus ni moins qu'une accumulation de couche de convolution et de pooling suivit d'un perceptron multi-couche.
Pour représenté ce paradigme,
TensorFlow a le type Conv2D qui permet de créer une couche de convolution.
Le constructeur de cette dernière prend en entrée, le nombre de filtre, la taille des filtres, et la fonction d'activation.
Exemple :
layers.Conv2D(64, (3, 3), activation='relu')
Pour créer une couche de pooling, il faudra utiliser la classe MaxPooling2D qui prend en entrée le facteur par lequelle l'on souhaite divisé la taille des images obtenu dans la couche précédente.
Exemple :
layers.MaxPooling2D((2, 2))
Pour finir, du fait que les couches soit bidimensionnelle, pour les envoyé en entrée du perceptron multicouche à la fin du réseau il va faloir les réduire à une dimension.
Cela est possible en se servant de la couche flatten, qui réduit à une dimension tout ce qui la précède.
layers.Flatten()
Le reste du réseau consite en généralement 2 ou 3 couche dense qui seront généralement 1 ou 2 couche caché et enfin une couche de sortie.
#Création du réseau de neurones
model = models.Sequential()
#Ajout d'une couche convolutionnel de taille 32 et de filtre 3 x 3
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28,1)))
#Ajout d'une couche pooling 2 x 2
model.add(layers.MaxPooling2D((2, 2)))
#Ajout d'une couche convolutionnel de taille 64 et de filtre 3 x 3
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
#Ajout d'une couche pooling 2 x 2
model.add(layers.MaxPooling2D((2, 2)))
#Ajout d'une couche convolutionnel de taille 32 et de filtre 3 x 3
model.add(layers.Conv2D(32, (3, 3), activation='relu'))
#Applatissement de la dernière couche pour l'envoyer en entrée d'une couche dense
model.add(layers.Flatten())
#Ajout d'une couche dense
model.add(layers.Dense(32, activation='relu'))
#Ajout d'une couche softmax
model.add(layers.Dense(10, activation='softmax'))
#Compilation du modèle, avec comme méthode d'entraînement adam (converge plus vite), et comme loss categorical_cross_entropy et comme métrique accuracy
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
#Entrainement du modèle
model.fit(train_images, train_labels, epochs=100,
validation_data=(test_images, test_labels))
#Évaluation du modèle
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
from __future__ import absolute_import, division, print_function, unicode_literals
#Importation des librairies nécessaires tensorflow, numpy, csv, os, scikit-learn,random
import tensorflow as tf
import numpy as np
import csv
import os
from tensorflow.keras import datasets, layers, models
from sklearn import preprocessing
import random
#Fonction de chargement du fichier train.csv contenant les caractère de mnist
def load_dataset():
a=0
train_images=[]
train_labels=[]
test_images=[]
test_labels=[]
#Initialisation de random
random.seed(30)
#Ouverture et lecture de train.csv
with open('train.csv', 'r') as csvfile:
myreader = csv.reader(csvfile, delimiter=',', quotechar='|')
i=0
for row in myreader:
if i!=0:
image_lbp=np.array(row[1:]).astype(np.float)
choix=random.randint(0,3)
#Un exemple sur 3 va dans la base de test le reste dans la base d'apprentissage
if choix==1 :
test_images.append(image_lbp)
test_labels.append(int(row[0]))
else :
train_images.append(image_lbp)
train_labels.append(int(row[0]))
i+=1
return train_images,train_labels,test_images,test_labels
train_images,train_labels,test_images,test_labels=load_dataset()
train_images = np.array(train_images)
#Mise en forme des données images de train et de test afin qu'elle soient comprises entre 0 et 1
min_max_scaler = preprocessing.MinMaxScaler()
train_images = min_max_scaler.fit_transform(train_images)
test_images = min_max_scaler.transform(test_images)
train_images2=[]
test_images2=[]
#Transformation de la ligne du fichier CSV en une image de 28 x 28 pixels
for i in range (0,len (train_images)):
train_images2.append(train_images[i].reshape(28,28,1))
for i in range (0,len (test_images)):
test_images2.append(test_images[i].reshape(28,28,1))
train_images=[]
test_images=[]
#Conversion de toute les liste en tableau
train_images=np.array(train_images2)
test_images=np.array(test_images2)
test_labels=np.array(test_labels )
train_labels=np.array(train_labels )
#Création du réseau de neurones
model = models.Sequential()
#Ajout d'une couche convolutionnel de taille 32 et de filtre 3 x 3
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28,1)))
#Ajout d'une couche pooling 2 x 2
model.add(layers.MaxPooling2D((2, 2)))
#Ajout d'une couche convolutionnel de taille 64 et de filtre 3 x 3
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
#Ajout d'une couche pooling 2 x 2
model.add(layers.MaxPooling2D((2, 2)))
#Ajout d'une couche convolutionnel de taille 32 et de filtre 3 x 3
model.add(layers.Conv2D(32, (3, 3), activation='relu'))
#Applatissement de la dernière couche pour l'envoyer en entrée d'une couche dense
model.add(layers.Flatten())
#Ajout d'une couche dense
model.add(layers.Dense(32, activation='relu'))
#Ajout d'une couche softmax
model.add(layers.Dense(10, activation='softmax'))
#Compilation du modèle, avec comme méthode d'entraînement adam (converge plus vite), et comme loss categorical_cross_entropy et comme métrique accuracy
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
#Entrainement du modèle
model.fit(train_images, train_labels, epochs=100,
validation_data=(test_images, test_labels))
#Évaluation du modèle
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
Classifier du Texte avec TensorFlow