La régression logistique -Logistic regression : en anglais- est un modèle de machine learning utilisé pour la résolution de problème de classification binaire tels que la diagnostique de maladie, la probabilité d'achat, la probabilité de churn, la probabilité que survienne un évènement.
Cet article a été divisé en trois grande partie :
Ce qu'est la régression logistique
Ce qu'est le maximum de vraissemblance " Maximum Likehood"
Comment est entraîné un modèle de régression logistique
La régression logistique se sert des probabilité afin de prédire la classe Y d'un exemple X=[X1,X2,.....Xn] avec X1, X2 ... Xn étant les données d'entrée avec lesquelle on veut prédire la sortie. En clair :
Y=reglogit(X)
A l'image de la régression linéaire, elle va se établir une relation linéaire entre la classe Y de l'exemple et les données X.
La classification est les processus qui consiste à attribuer de manière automatique une étiquette à des données. Dans le
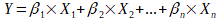
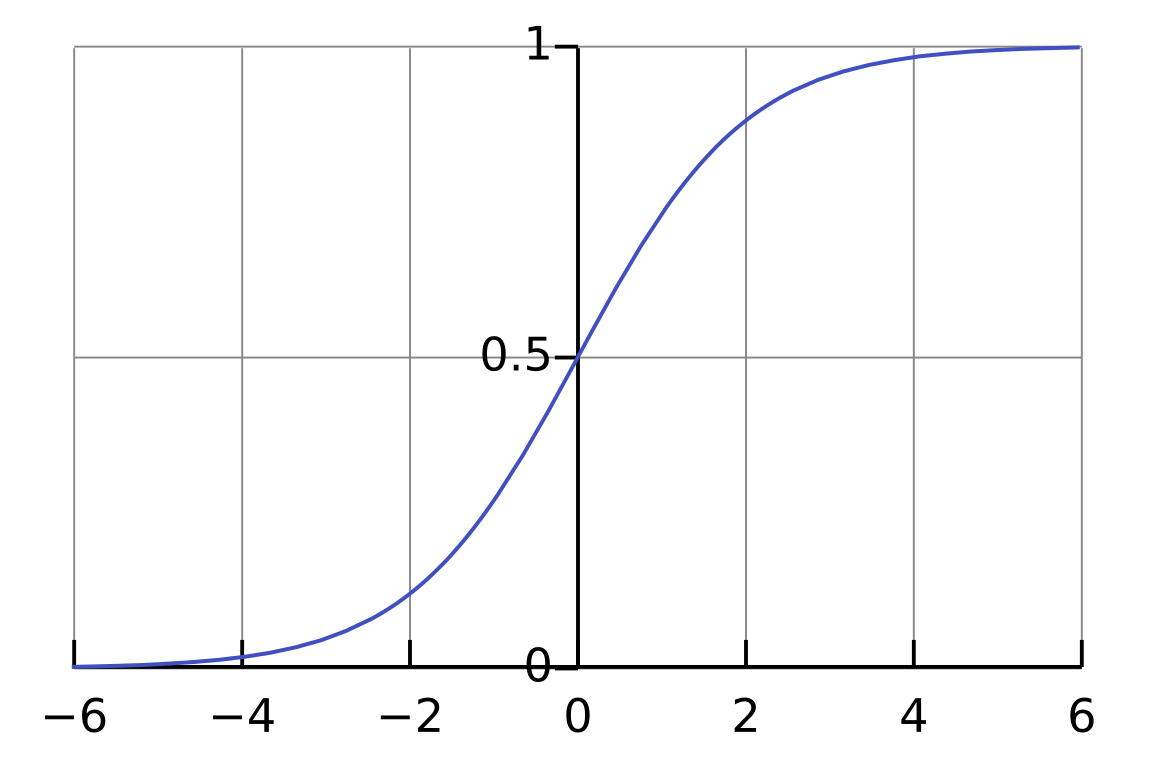
La formule ci-dessus, n'est pas tout à fait vrai. Car lors de la régression logistique, ce que nous cherchons à obtenir c'est la probabilité que Y appartienne à la classe 1 ou à la classe 2. Une probabilité étant comprise entre zéro et un, il faut trouver un moyen de borner le résultat. Cela se fait a l'aide de la fonction logistique qui en faite est la fonction sigmoid très utilisé dans les perceptron multi-couches. Cette fonction est représenté sur l'image ci-dessous:
La formule permettant d'obtenir la sigmoid étant :
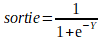
La formule devient alors
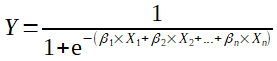
C'est la probabilité d'obtenir d'obtenir la classe 1 selon les données X. Si elle est inférieur à 0.5 l'on considère que la classe de l'exemple est zéro, et à l'inverse si cette probabilité est supéreur à 0.5 l'on dira que la classe de l'exemple est 1.
Premièrement, il faut savoir ce que likehood signifie en français. Avec une petite recherche sur google translate vous vous rendrez compte que likehood signifie vraisemblance donc maximum likehood signifie maximum de vraisemblance mais que ce terme a aussi rapport au probabilité.
Quand l'on entraîne un classifieur, il constuit une distrbution de probabilité qui permet de savoir qu'elle est la probalité d'obtenir Y selon X.
Pour faire simple, nous avons un modèle de probabilité h et de données x et l'on va maximiser la probabilité de Y sachant cela
maximiser P(Y | x ; h)
Le but d'un modèle sera d'obtenir les P(x) selon h . P(x
La régression logistique est un modèle de classification binaire.
Soit X un vecteur d'entrée, y la classe et logit un modèle de régression logistique alors :
y=logit(X)
y= X1*beta1 + X2*beta2 + .... + Xn*betan
Afin que la valeur de sortie soit comprise entre zéro et 1, une fonction est utilisée
Puis cette somme est envoyé dans une fonction de d'activation généralement la fonction sigmoid
on obtiens alors une valeur comprise entre zéro et 1 qui est une la probabilité que les données appartiennent à la classe 1.
beta est estimé en entraînant le modèle sur les exemples
Il existe plusieurs moyens d'estimer ces paramètre
chance de gagner les chances logarithmique de gagner
Maximum de vraisemblance (Maximum likehood : en anglais) permet d'estimer les paramètre du modèle.
Maximiser les chances d'observer X selon une distribution de probabilité et ses paramètre?
La log likehood c'est le log de la somme de la probabilité d'observé chacun des exemples selon les paramètre du modèle
Source :