Une des anecdotes marrantes que j'ai avec Weka et des cours de data-mining est l'histoire des bières et des couches !
Le délire vrai est le suivant :
Des scientifiques américains spécialisés dans le data mining ont mené une étude sur les produits fréquemment achetés ensemble en supermarché !
Et il a été remarqué que le dimanche, beaucoup d'hommes venaient acheter des couches pour leur bébé et que très souvent ces derniers repartaient avec en plus des couches un pack de bière !
Probablement je pense pour boire devant un match de foot !
Ou peut-être pour programmer.
À l'université j'avais un pote qui programmait, mais que quand il était bourré !
Il disait que ça lui permettait de mieux se concentrer !
Et si ce n’était pas l'alcool ! ben c'était de la beuh qu'il prenait !
Conséquence, il était bien souvent Tchad en cours !
Mais le plus ironique de toute cette histoire c'est qu'il était major de promo et dépassait le second d'au moins 2 points !
Et chaque matin, il venait avec son p’tit gobelet et sa bouteille de whisky en cours.
Quoi qu'il en soit, revenons à nos moutons !
Je disais que le data-mining comme le disais ma prof de data-mining, c'était l'art de trouver des pépites de connaissances dans un amas de données !
d'ou le terme data mining qui signifie "minage de donnée".
C'est d'ailleurs exactement ce que permet de faire le logiciel Weka qui est juste horriblement génialissime
À tel point que pour moi c'est le meilleurs de tous les logiciels pour faire du machine learning et du data-mining à petite échelle.
Pour faire du data-mining à grande échelle il faut d'intéresser aux solutions de Big Data telles que MPI, spark ou encore hadoop, qui est réputé pour cela!
Dans cet article, je vais vous faire une présentation du logiciel Weka et de ses différentes fonctionnalités
Et j'espère bien qu'après tout cela, tu seras également convaincu que Weka est un logiciel juste badass.
Dans cet article, je verrais avec toi :
C'est quoi Weka ?
Pourquoi utiliser Weka ?
Par la suite, je décortiquerais chacune des grosses fonctionnalités de ce logiciel (Comme cela, tu auras une idée de tous ce qu'il est possible de faire avec).
Le prétraitement de données en utilisant l'onglet "preprocessing"
La classification grâce à l'onglet "classification"
Le clustering, onglet "clustering"
La sélection de caractéristiques avec l'onglet "Feature Selection"
Visualiser des données avec l'onglet Visualise
Weka est un logiciel libre de datamining développé en java par l’université de Waikato et publié sous licence GNU General Public License.
Son développement à commencé en 1992 en C, puis en 1997 l’équipe de développement à décider d’utiliser le langage java.
Weka est utilisé par les data scientist à des fins d’analyse de données.
Il présente de nombreux avantages tels que la
et enfin une
tels que les Réseaux de neurones, les arbres décisionnels, où encore les k-moyennes .
La grande particularité de Weka par rapport à d’autres frameworks de machine learning est que celui-ci dispose d’une interface graphique ce qui lui permet d’être manié par des néophytes.
Mais également pour les plus expérimentés d'une bibliothèque Java qui permettra à ces derniers de passer de la phase d'expérimentation à la phase industrielle.
Un des points pour lesquels j'apprécie particulièrement Weka et tu pourras probablement le constater si tu le télécharges c'est
Deux, trois clics et le tour et quelque minute et le tour est joué, nous retirons de nombreux insight sur les données avec Weka.
La preuve en est que le premier onglet de Weka après avoir ouvert un jeu de données est le suivant :
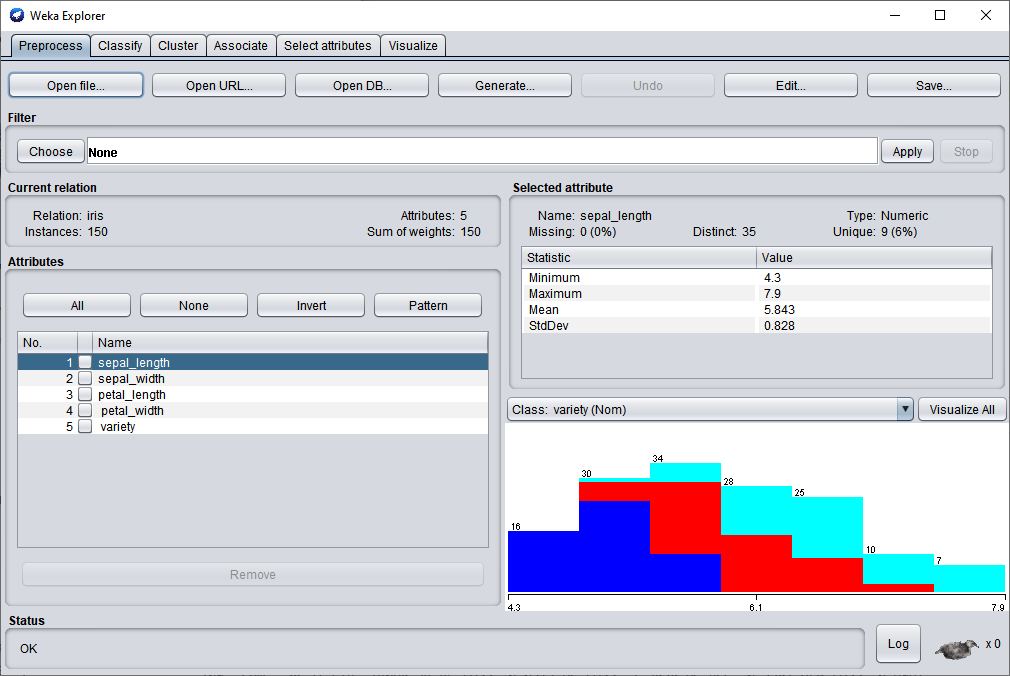
Tu remarqueras qu'il y a le nombre de données, le nom de chaque colonne du jeu de données, la variance, la moyenne pour chaque colonne du jeu de données.
Mais aussi la répartition des données tout en bas à droite.
Rien qu'avec cela, on peut déjà en tirer quelque chose alors que l'on vient à peine d'ouvrir le logiciel.
Tu trouveras Weka sur son site officiel, il te suffit d'aller dans la section Download pour le télécharger.
tu auras alors le choix entre 4 versions de Weka, 2 pour les machines 64 bits et 2 pour les machines 32 bits.
Bien sûr la le choix n'est pas difficile de nos jours, il est très fort probable que ta machine soit 64 bits.
Il nous reste donc 2 choix.
Celui où c'est marqué "Oracle's 64-bit Java VM 1.8" installe la machine virtuelle Java qui est nécessaire à Weka en plus de Weka.
Si tu as déjà installé Java sur ton ordinateur, tu n'as pas besoin de cette version.
C'est la seconde "without a Java VM" qu'il te faudra prendre.

Une fois téléchargé et installé tu pourras l'ouvrir, tu obtiendra alors cette fenêtre.
Télécharge le jeu de données que voilà :
Normalement tu devrais avoir la fenêtre suivante :
et sélectionnez csv comme type de fichier puis ouvre le fichier Iris.csv que tu viens de télécharger.
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
6.0,2.9,4.5,1.5,Iris-versicolor
5.7,2.6,3.5,1.0,Iris-versicolor
7.9,3.8,6.4,2.0,Iris-virginica
6.4,2.8,5.6,2.2,Iris-virginica
Un fois que tu a chargé Iris.csv, tu obtiens une fenêtre comme celle ci-dessous :
Tout en haut de la fenêtre tu a probablement pu le remarquer, il y a plusieurs onglet. Chacun des onglet te permet d'accéder à un des
Tous les onglets de Weka sont assez simples de prime abord.
Mais si l'on n’a pas une solide expérience du machine learning, il est possible que l'on sous-estime Weka à cause de cette simplicité qui le caractérise.
J'en ai d'ailleurs fait l'expérience à mes frais, car durant de nombreuses années j'ai préféré programmer plutôt que d'utiliser Weka alors que celui-ci a actuellement les
que l'on puisse trouver sur le marché.
C'est la raison pour laquelle, je te recommande de pencher très sérieusement sur ce logiciel.
Il est aussi simple que puissant !
Tous les algorithmes qui y sont implémentés à l'intérieur le sont dans la version la plus optimisée qui soit.
En plus de cela, Weka à une stabilité de dingue et ne plante jamais.
Sauf dans le cas où l'on traite un jeu de données tellement gros que Weka a besoin de plus que la quantité de RAM disponible sur l'ordinateur pour fonctionner.
Quoi qu'il en soit, l'onglet 'preprocess' n'échappe pas à la règle, il est extraordinairement simple, mais également extraordinairement puissant.
Il ne me sera pas possible de décrire toutes les fonctionnalités de Weka dans cet article.
Si tels étaient, le cas, cet article serait trop long, mais je vais tenté de décrire au mieux l'onglet 'preprocess'.
L'onglet 'preprocess' comme son nom l'indique est un onglet qui permet de prétraiter les données que l'on insère dans Weka.
Il se peut que tu ne voies pas très bien qu'elle est l'utilité de prétraiter les données.
Cela se comprend, car dans de nombreux cas, cela n'est pas toujours nécessaire.
Je vais donc prendre différents exemples dans lesquels tu auras à prétraiter des données
Si tu connais bien les réseaux de neurones, tu sais qu'il faut absolument centré réduire les données avant de les envoyé en entrée de ce dernier.
Pendant des années, je n'étais pas au courant de cela, l'être m'aurait évité bien des galères. Un jour, je me suis retrouvé pendant plusieurs jours coincé! je ne comprenais pas pourquoi le modèle ne fonctionnait pas.
J'ai fini par pur hasard par centrer réduire les données et ça a résolu le problème.
Centrer et réduire les données avec Weka te sera très utile dans le cas ou tu veux afficher un graphique.
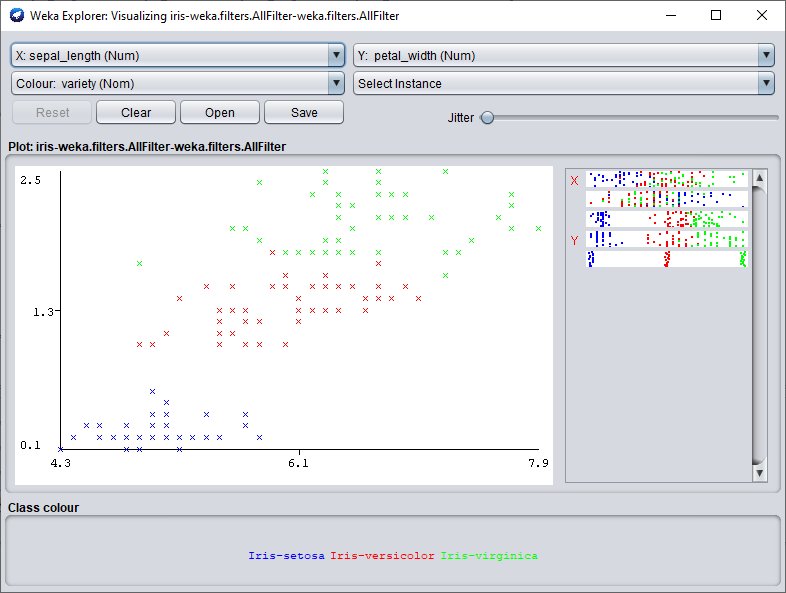
Par exemple si tu regardes sur l'image ci-dessous, j'ai mis un graphique qui regroupe 5 exemples chacun appartenant à une classe différente.
Sur le graphique l'on aurait juré que c'est la même classe de prime abord.
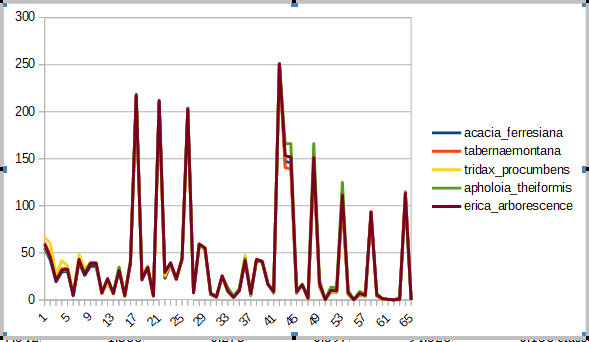
Mais après avoir centré et réduit les données avec Weka, l'on se rend compte qu'il s'agit bel et bien de 5 classes différentes.
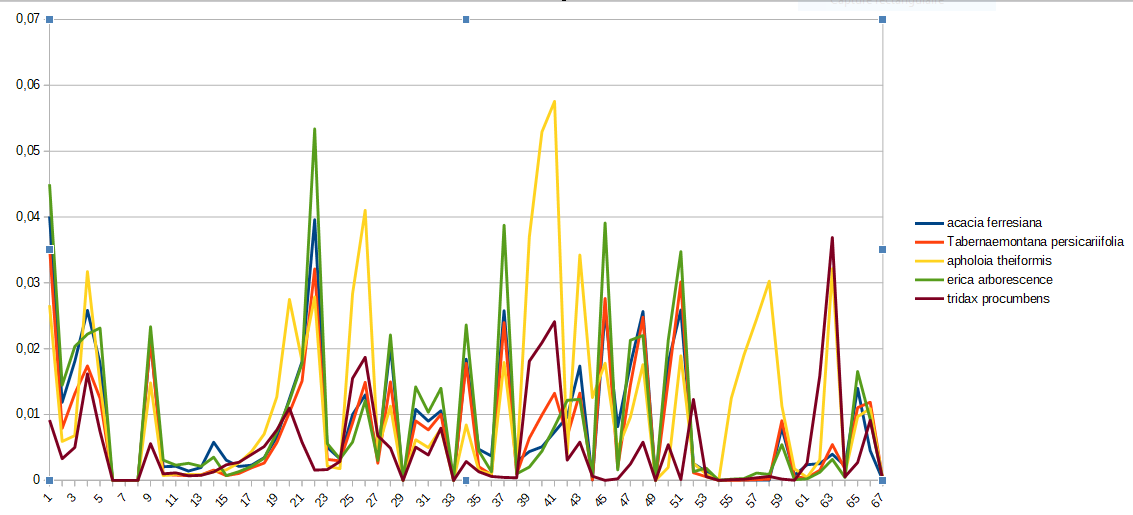
Si toi aussi, tu veux être capable de centrer et réduire des données avec Weka tu pourras le faire en
Depuis l'onglet 'preprocess'.
La boite de dialogue des filtres apparait. Il s'agit d'une boîte de dialogue qui contient tous les filtres de prétraitement de données que propose Weka.
Tu trouveras dans celle-ci 2 grandes catégories de filtre
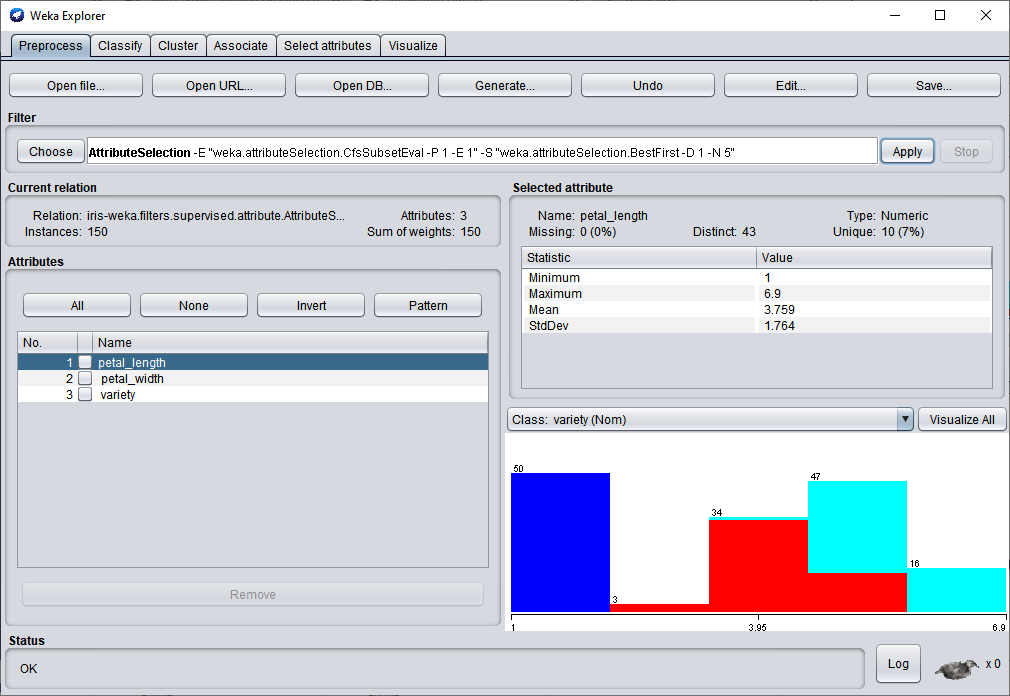
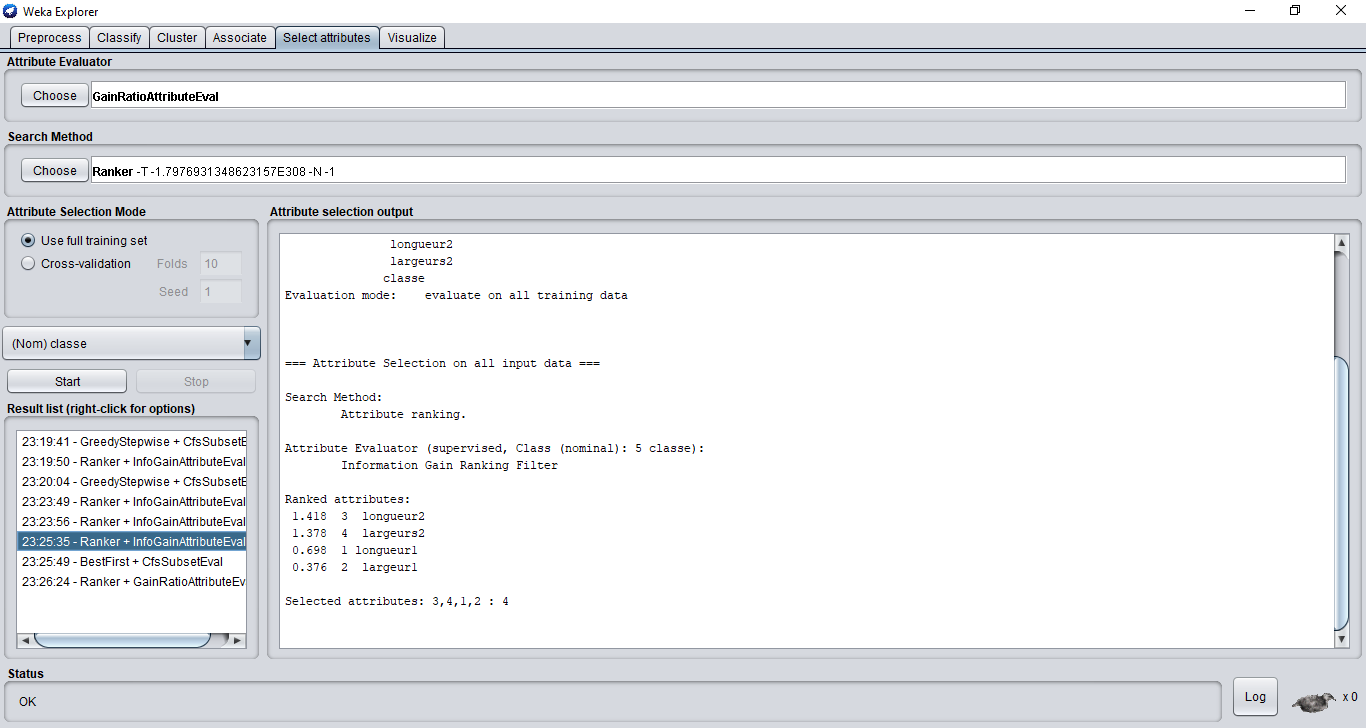
Exemple "AttributeSelection":
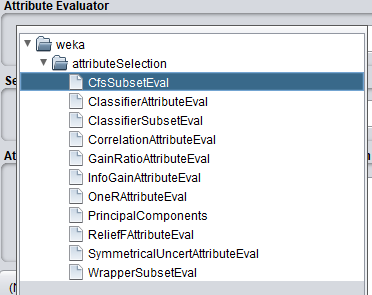
Un filtre que moi j'aime particulièrement est "Attribute Selection", il permet de sélectionner les caractéristiques les plus importantes pour le problème traité.
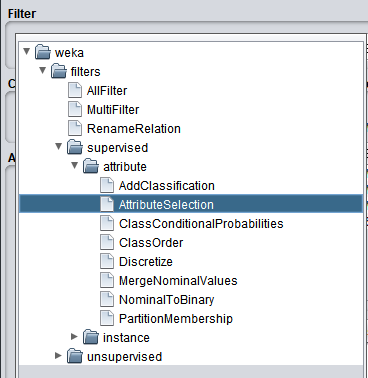
Imagine que tu sois dans un cas ou tu as un jeu de données qui a des dizaines de milliers d'attributs (ce qui m'est déjà arrivé).
En utilisant le filtre attributeselection, tu pourras sélectionner que les attributs les plus pertinents pour la résolution de ton problème.
L'avantage de faire cela est triple :
Premièrement tu allégeras ton jeu de données en ne gardant que celles qui sont utiles.
Deuxièmement grâce à cela, tu pourras entraîner des modèles en beaucoup moins de temps. Imagine que tu as 10 000 attributs, mais que attributeselection ne t'en sélectionne que 10 tu auras au moins accélérer le temps d'entraînement de ton modèle d'un facteur de x1000.
Pour finir troisièmement, ce sera bien plus facile pour toi d'afficher graphiquement les données et d'en ressortir des pépites de connaissances.;-)
et les
Résultat de l'application de "AttributeSelection" sur le jeu de données Iris.csv :
Les filtres non supervisés, permette de faire des actions moins évoluées sur les jeux de données telles que supprimer manuellement des attributs, modifier des attributs en utilisant une formule mathématique ou encore centrer réduire les données.
Ci-dessous j'ai fait une petite liste des filtres non supervisés les plus utiles.
Remove
Permet de supprimer des attributs.
AddExpression
Permet de construire un nouvel attribut à partir d'une expression mathématique.
AddID
Ajoute un id à chaque instance du jeu de données.
Center
Centre les attributs du jeu de données de telle sorte que leur moyenne soit égale à 0.
DateToNumeric
Convertis les dates en millisecondes.
Standardise
Standardise les attributs du jeu de données de telle sorte que leur variance soit égale à 1.
ReplaceMissingValues
Remplace les valeurs manquantes du jeu de données par la moyenne, ou le mode de chaque attribut.
StringToWordVector
Convertis un texte en vecteur de valeur numérique représentant les occurrences de chacun des mots dans le texte.
Pour centrer réduire le jeu de données il te suffit d'appliquer le filtre center puis le filtre standardise.
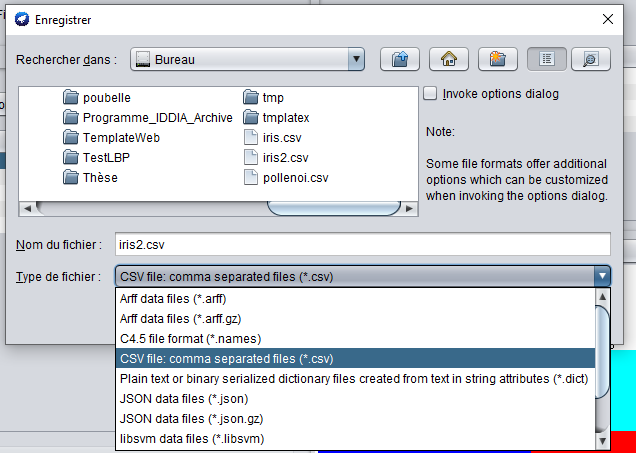
Cela fait, tu peux enregistrer le jeu de données centré réduit au format que tu souhaites en cliquant sur "Save ..."
Une fenêtre "Enregistrer" apparaît.
Tu choisis alors ton format favori parmi les suivants Arff, CSV, JSON, ...et tu rentres le nom de ton fichier
En l'occurrence mon format favori à moi c'est le CSV car ensuite je peux importer le jeu de données dans Excel ou google sheet et faire des graphiques tels que ceux que je t'ai montrés plus haut.
Le format ARFF est un format qui a été créé spécialement pour Weka. Auparavant je pensais que ce format était un format comme un autre.
Cependant un jour j'avais du mal à traiter un jeu de données, je ne cessais de cliquer sur le bouton pour faire de la classification, mais il ne se passait rien. Weka buguait (ce qui est super rare).
Il m'a suffi de réenregistrer le jeu de données sous le format "arff" et d'ouvrir le nouveau fichier pour que Weka arrête de bugé
Autrement dit, certaines fois il peut arriver que tu aies des bug avec les autres formats.
Si c'est le cas, je te conseille de passer direct au Arff qui est le format officiel de Weka et de rouvrir ton fichier dans ce format, il se peut que cela te débloque
La box Current Relation
La "Current Relation" Box, indique le nom du jeu de données courant, son nombre d'exemple et d'attribut et la somme des poids de la totalité des exemples.

L'"Attributes" Box, affiche les attributs du jeu de données courant. Elle permet également de sélectionner ou de supprimer des attributs avec le bouton "Remove".
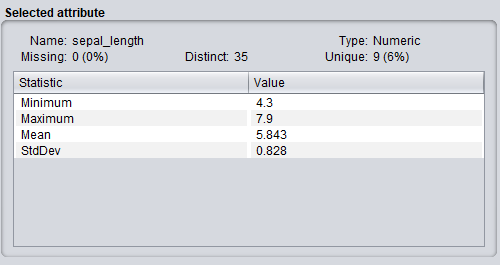
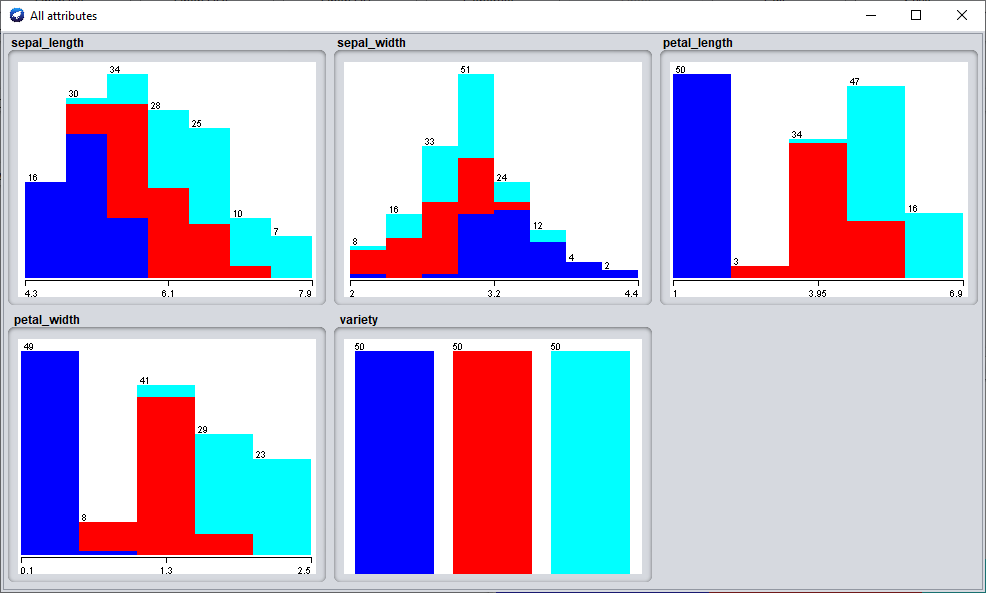
La "Selected Attribute" box, affiche les propriété statistique (moyenne, min, max, histogramme, ...) de l'attribut couramment sélectionné. En cliquant sur "Visualize All", vous pouvez visualiser l'histogramme de l'ensemble de tout les attributs simultanément
Exemple :
La "status" box nous donne des informations sur l'opération que Weka est en train ou d'effectuer. Le nombre d'opération en cours est indiqué par l'oiseau à droite.
Exemple 1 : Tout va bien

Exemple 2 : Weka construit un modèle en cross-validation.

En cliquant sur log, vous pouvez accéder à l'historique des actions que vous avez effectuées jusqu’à maintenant :
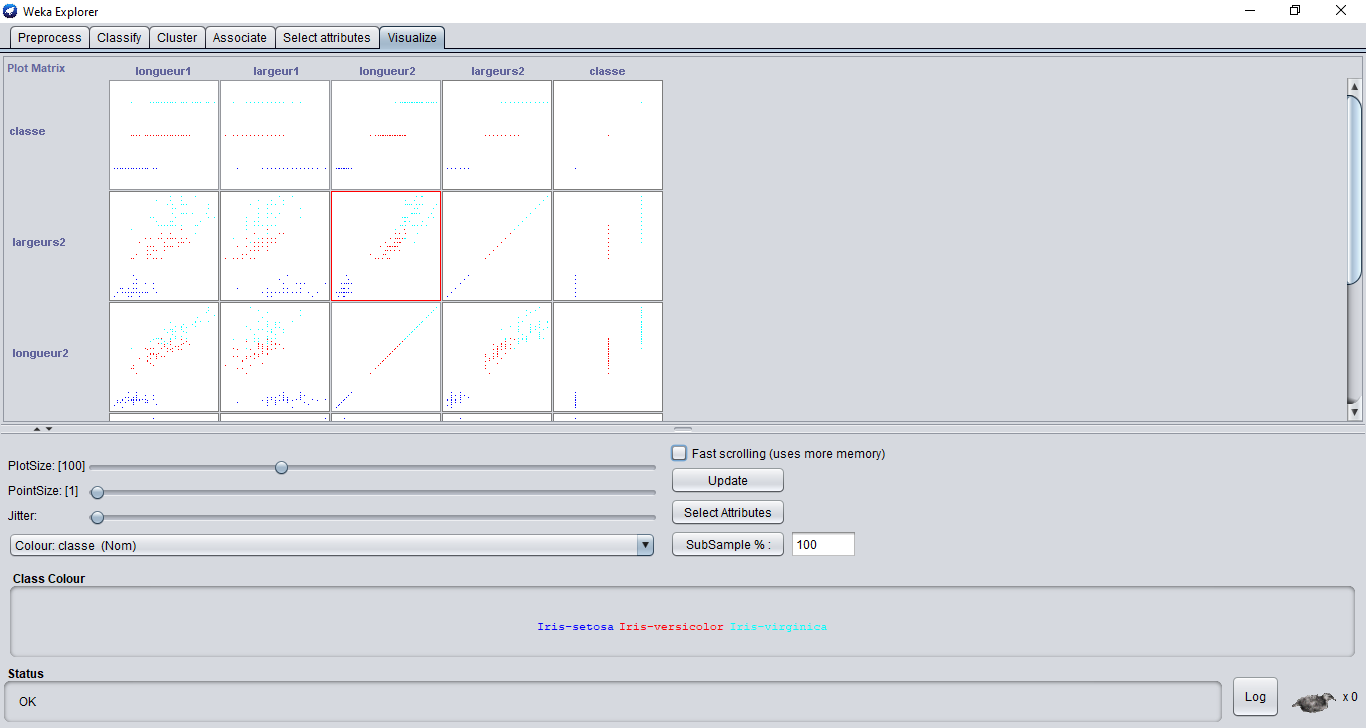
Weka dispose de l'onglet visualisation qui propose des graphiques 2D montrant la répartition des instances du jeu de données par rapport aux caractéristiques sélectionnées par l’utilisateur.
En cliquant sur un des graphiques, une fenêtre contenant ce dernier apparaît.
Dans l’onglet classification, Weka implémente les modèles les plus populaires de machine learning tels que : Les Réseaux de neurones, Forêt d’arbres décisionnels, arbre de décision, Réseau de bayes, support vector machine, Logiboost, Adaboost, JR48, …
Personnellement dans cette article, je vais en tester 3 que j'aime bien et qui en général permette d'obtenir de très bonne performance. Il s'agit de l'arbre de décision JR48, le Random Forest et le perceptron multicouches.
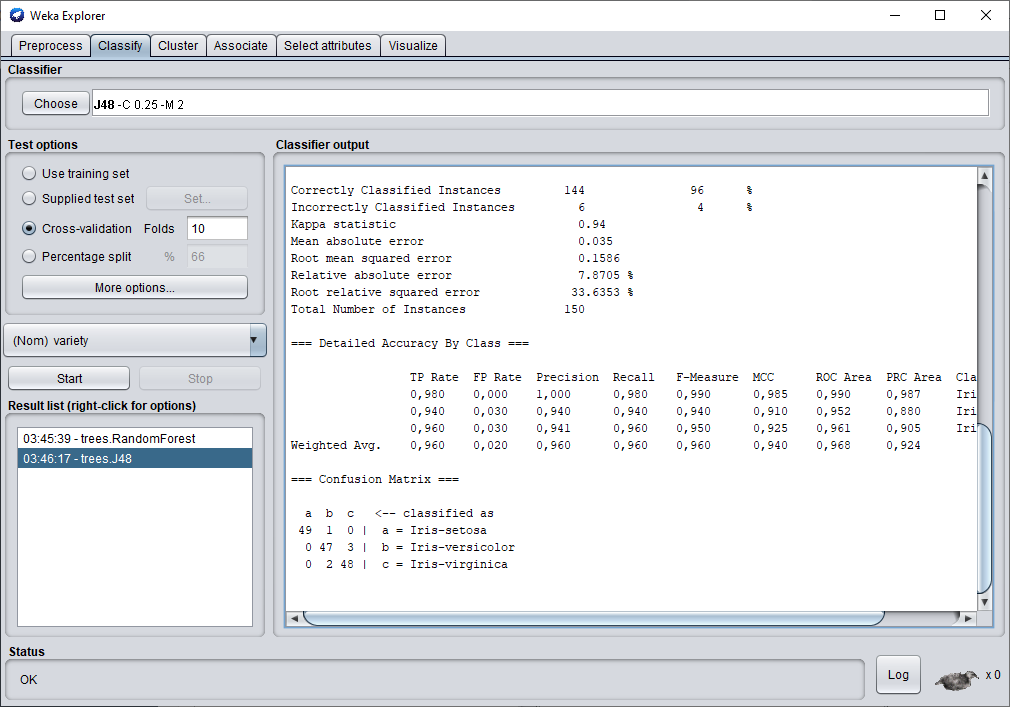
Weka est par défaut configuré en cross-validation c'est pourquoi pour commencer le test en cross-validation, il suffit de cliquer sur start et le test se lance alors.
Avec l'arbre de décision JR48, nous obtenons une performance de 96 % d'exemple correctement classé. C'est plutôt pas mal.
Une fois la classification terminée en scrollant la fenêtre tu peux voir l'arbre de décision et les critères qu'il a utilisés pour faire sa classification.
Voyons maintenant ce que l'on obtient en utilisant le Random Forest.
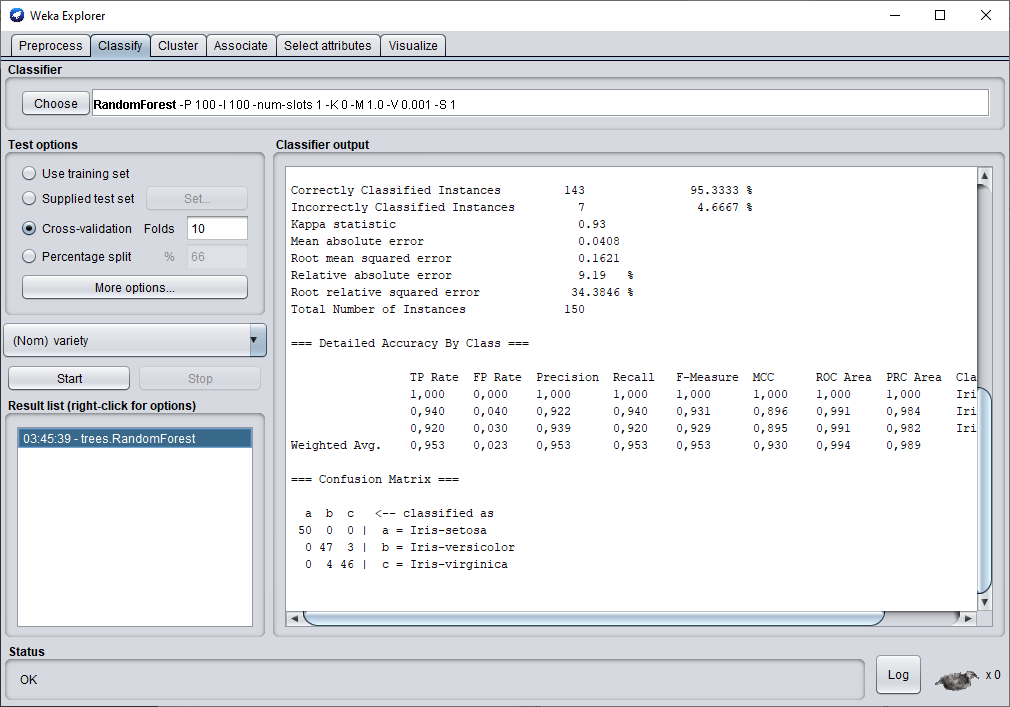
Nous obtenons une performance moins bonne qu'avec l'arbre de décision classique.
Honnêtement ce résultat est un peu surprenant quand on sait qu'un randomForest est un ensemble d'arbres de décision et que le principe reposant derrière ce modèle est de combiner plusieurs arbres décisionnels différents afin de prendre une meilleure décision
. dans ce cas-ci Weka n'affiche pas le modèle, car il est trop long d'afficher 100 arbres de décision.
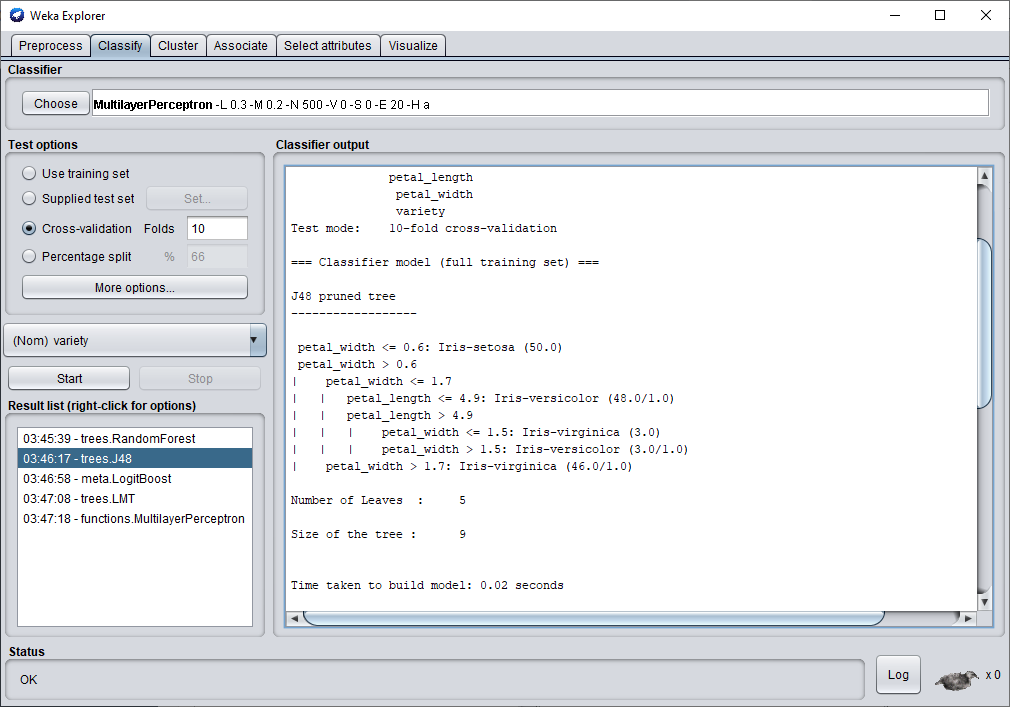
Nous finirons ce test avec le perceptron multicouches.
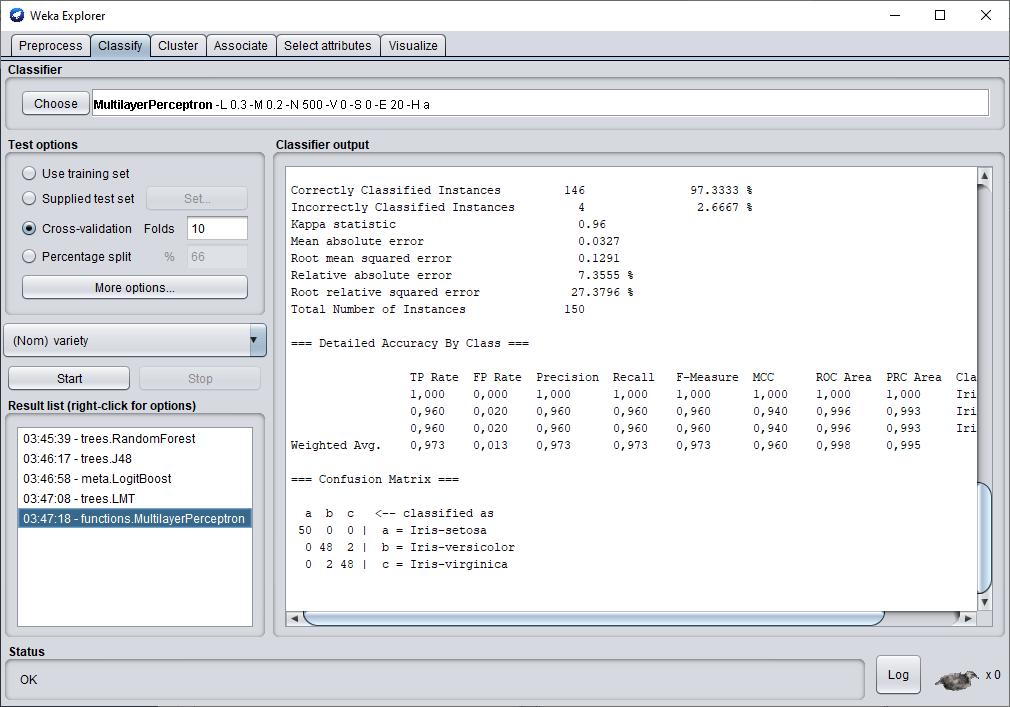
En utilisant le perceptron multi-couches, nous avons réussi à obtenir un taux de classification de 97.33 %.
C'est supérieur au résultat obtenu par l'arbre de décision et par le random Forest. Par conséquent , c'est le modèle qui sera retenu pour ce jeu de données.
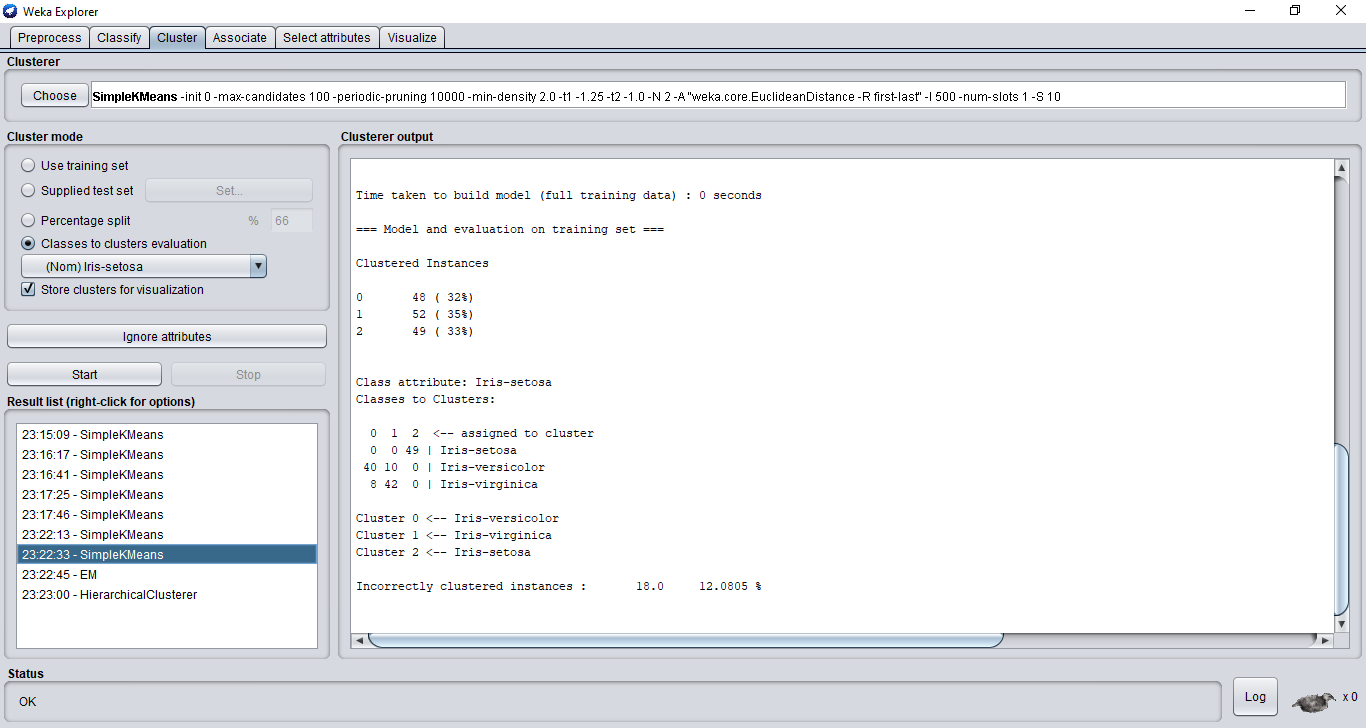
En plus des algorithmes de classification nommés ci-dessus, Weka propose les différents algorithmes de clustering suivants :
Cobweb, espérance-maximisation, k-moyennes, DBSCAN, Hierarichical Clustering, Density based clusterer, ...
Weka offre en plus des onglets, preprossecing, classifications et clustering un onglet feature selection. Cet onglet permet de sélectionner les caractéristiques du jeu de données étudiées les plus pertinentes pour le traitement que l’utilisateur souhaite faire.
https://www.cs.waikato.ac.nz/ml/weka/
https://en.wikipedia.org/wiki/Weka_(machine_learning)
https://fr.wikipedia.org/wiki/Weka_(informatique)
 Tu as aimé ce tutoriel et tu as pour objectif de devenir un vrai monstre de la vision par ordinateur et du machine learning.
Tu as aimé ce tutoriel et tu as pour objectif de devenir un vrai monstre de la vision par ordinateur et du machine learning.
Mais tu n'as pas de temps pour apprendre.
As-tu 5 à 10 minutes par jour pour lire un email ?
Si c'est le cas inscris-toi gratuitement à la newsletter par email de kongakura.fr et participe dès à présent à une formation quotidienne continue par email à la vision par ordinateur, aux machine learning et deep learning.
En t'inscrivant, tu recevras chaque jour une leçon de 5 à 10 minutes de lecture.
En plus de cela, tu recevra des cours, des tutoriels, des astuces et des conseils, afin que tu deviennes le meilleur de ces domaines et que tu sois au courant au plus tôt des dernières nouveautés.
Ne manque pas la leçon de demain matin !
N'hésite pas à tester la newsletter, tu n'as rien à perdre si ce n'est ton temps et tu comprends que tu peut te désinscrire à tout moment de la formation avec le lien que je laisse au bas de chaque email.