Le deep learning est un champ du machine learning qui a fait énormément parler de lui ces dernières années notamment du fait de toute les promesses qui y sont liées.
De nombreuses personnes y ont même prédit la fin de l'intelligence humaine voire même de l'humanité.
Bon OK, la j'exagère un peu. Et je vous troll.
Néanmoins, les ingénieurs à l'origine des algorithmes de deep Learning sont directement allés chercher leur inspiration dans la configuration des neurones du cerveau humain pour concevoir les algorithmes de deep.
Et force est de constater que ça a plutôt bien réussi et qu'un grand bond dans l’intelligence artificielle a été constaté.
Si tu débutes dans le machine learning, tu as très probablement entendu parler du Deep Learning.
Et du coup, tu te demandes très probablement :
Surtout que ces derniers temps, ça jazz grave à propos du deep learning. Dont on ne cesse de raconter les prouesses.
Dans cet article, nous verrons :
Qu'est-ce que le machine learning ?
Qu'elles sont les tâche pour lesquelles, il est possible d'utiliser le machine learning ?
Qu'est-ce que le Deep Learning ?
Qu'est-ce qui change réellement avec le Deep Learning ?
Un comparatif des cas d'utilisations Deep learning vs machine learning
Un comparatif des algorithmes Deep learning vs machine learning
Un comparatif des bibliothèques Deep learning vs machine learning
Un comparatif des livres Deep learning vs machine learning
Le machine learning, c’est l’ensemble des algorithmes capable de résoudre automatiquement un problème en se servant d’informations extraites du problème.
Ce qui différencie les algorithmes de machine learning des autres algorithmes, c’est leurs capacités
Ils s’appuient donc moins sur l’expertise humaine dans leur conception et n'ont donc pas besoin de l’humain pour s'adapter à des problèmes similaires.
Sous-ensemble de techniques d'apprentissage regroupant toutes les techniques d'apprentissage machine utilisant des réseaux neuronaux profonds (Deep: en anglais) pour apprendre.
Généralement, l’apprentissage machine est utilisé pour la résolution de différent problème générique tel que
-La classification (Trier des objets en apprenant sur avec des données d'objets déjà triés)
-La régression (Prédire l’évolution d’une fonction)
-Le clustering (Trier des objets)
-La génération (Générer des données inexistantes).
Contrairement à ce que tente de nous faire croire les médias, le Deep Learning n'a pas tant apporté de nouveautés que ça au machine learning.
Je dis cela dans le sens ou la majorité des tâches que l'on effectue maintenant en utilisant le Deep Learning,
avec le machine learning.
C'est juste qu'on les faisait moins bien.
La preuve en est que :
Avant l'arrivée du deep Learning, nous savions déjà comment faire de la reconnaissance de visage ou encore de la reconnaissance vocale.
Pour cela les chercheurs construisaient des modèles mathématiques complexes qui leur permettaient de modéliser et d'extraire les informations importantes des données.
Par exemple, dans le cas d'une image, ils cherchaient à extraire des informations tels que l'aire des objets, le périmètre, ou encore les moments de ces derniers.
Processus un peu long, mais qui fonctionne et qui est toujours très utilisé de nos jours.
D'autant plus que ce type de modèle fait à la main présente l'avantage d'être véritablement très généraliste et donc de fonctionner même avec très peu de données.
Autre exemple,
Pour ce qui est du traitement automatique du langage, avant l'arrivée du deep learning, les chercheurs utilisaient couramment ce que l'on appelle les chaînes de Markov.
Il s'agit d'un modèle mathématique qui permet d'analyser efficacement les séries temporelles et d'effectuer des prédictions avec. Ce modèle a longtemps été utilisé pour la reconnaissance vocale.
Mais peu s'appliquer à tous les processus pour lesquels l'issue est déterminée par une suite d’événements, comme l'analyse de séquences vidéo ou encore de cours boursier pour les traders ^^.
Après l'arrivée du Deep Learning, ces derniers ont été remplacés par les réseaux neurones récurrents, qui sont nettement plus efficaces.
Troisième et dernier exemple,
L'extraction de caractéristiques automatique n'est pas née avec l'avènement du deep learning, contrairement à ce que l'on pourrait tenter de faire croire.
Avant cela, bien d'autres méthodes existaient pour ce faire telles que :
l'analyse en composante principale
l'analyse factorielle
ou encore l'analyse en composante indépendante.
Ce que je veux dire par tout cela c'est qu’en soi, la plupart des tâches qui sont effectuées de nos jours avec le deep learning,
nous pouvions d'ores et déjà les effectuer avec le machine learning conventionnel.
C'est juste que c'était plus compliqué et qu'il fallait obligatoirement être ingénieur en machine learning pour pouvoir véritablement s'en sortir et obtenir des performances de malades.
La seule vraie révolution majeure pour moi avec le Deep Learning que quasi aucun algorithme ne pouvait faire avant est
Et oui, si tu as suivi les informations récemment, tu as très probablement entendu parler des GAN, pour générative adversarial network.
Il s'agit de réseaux neuronaux qui permettent de créer de données inexistantes.
Cela peut être des visages de personnes inexistantes
ou encore des images de mangas, à tel point que bientôt je crois bien que l'on utilisera cette technique pour générer des bandes dessinées
ou encore transformer des phrases en images. Cette fonctionnalité-là sera plutôt à mon avis utilisée dans un futur lointain pour faire des adaptations filmographiques de nos romans préférés à moindre coût.
Quand on parle de machine learning, généralement, les données utilisées sont des informations extraites de données brutes du problème.
Tandis que quand l’on parle de Deep Learning, il s’agit majoritairement de données brutes qui sont utilisées.
Bien souvent quand on parle de machine learning, les données utilisées sont des données structurées c’est-à-dire des informations qui ont été extraites des données du problème grâce à une méthode mise au point par un ingénieur en machine learning.
Quand l’on parle de machine learning, de manière générale, l’on s’attend à ce qu’un ingénieur en machine learning construise un modèle qui sera capable d’extraire des informations clés des données du problème.
Tandis que quand l’on parle de deep learning, les données brutes sont envoyées à un réseau de neurones qui s’occupera d’extraire lui-même les informations contenues dans les données.
Pour finir, pour entraîner un modèle de deep learning, il faudra nettement plus de données, de ressources de calcul et de mémoire de stockage que pour entraîner un modèle classique de machine learning.
Cela est dû au fait que les réseaux de neurones contrairement aux humains n’ont pas d’information à priori des données.
Ils sont donc obligés d’explorer tous les modèles possibles afin de se rapprocher du modèle idéal.
Le deep learning est une approche reposant exclusivement sur la puissance de calcul des ordinateurs.
Ces racines reposent sur le fait que l’ordinateur est capable de construire un meilleur modèle que l’humain, car contrairement à ce dernier qui utilise son intuition pour trouver le meilleur modèle, les algorithmes de deep learning utilisent des concepts probabilistes et donc plus fiables afin de trouver le meilleur modèle.
-Si vous n’avez pas beaucoup de données
-Si vous avez des données structurées
-Si le problème ne se prête pas à l’utilisation du deep learning
Si vous avez beaucoup de données
Si vous ne disposez pas d’ingénieurs en machine learning pour construire le modèle
Si vous disposez de beaucoup de puissance de calculs et d’une capacité de stockage suffisamment grande.
Voici une liste non exhaustive de différents modèles de machine learning
-K-nearest neighbors (« k-plus proches voisins » en français) (classification)
-Décision tree « Arbre de décision » (classification)
-Support Vector Machine « Machine à vecteurs supports » (classification)
-Logistic regression Tree « Arbre de régression logistique ». (Régression)
-K-means « k-moyenne », Mean-shift, Expectation-Maximisation « espérance-maximisation » (clustering)
-Latent Dirichlet Allocations (clustering)
-DBSCAN (clustering)
…
-Multi-Layer Perceptron (« Perceptron multi-couche » en français)
-Convolutionnal neural network « Réseaux convolutionnelle de neurones »
-Long Short Term Memory Neural network « Réseau de neurones à mémoire court-longue terme »
-Reccurent neural network « Réseaux de neurone réccurent »
-Autoencodeur « Autoencodeurs »
-Adversarial neural network « Réseau génératif antagoniste »
Intelligence artificielle 3e édition : Avec plus de 500 exercices
L'Intelligence Artificielle pour les développeurs - Concepts et implémentations en Java
Big Data et Machine Learning - 2e éd. - Les concepts et les outils de la data science
Machine learning avec Python - collection O'Reilly
Intelligence artificielle et Cognitive business
Comprendre le Deep Learning: Une introduction aux réseaux de neurones
Deep Learning avec TensorFlow - Mise en oeuvre et cas concrets
TensorFlow pour le Deep learning - De la régression linéaire à l'apprentissage par renforcement
-La création d’avatars client et la segmentation de marché
-Les recommandations personnalisées
-La détection et la quantification des tumeurs.
-La prévision des rendements des cultures

Le Deep learning existait déjà depuis les années 90, mais ce n'est que vers la fin des années 2010 qu'il a connu une croissance et une expansion fulgurante.
Comme en témoigne la courbe ci-dessous qui montre le nombre d'articles de recherche dans le domaine biomédical qui ont utilisé le deep learning.
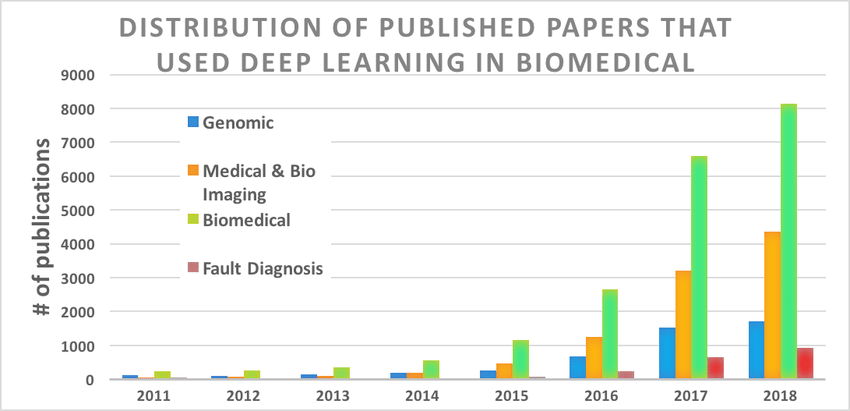
Source de l'image : Deep Learning in the Biomedical Applications: Recent and Future Status
Trois détonateurs principaux ont permis l'émergence du deep learning :
L'invention des réseaux de neurones convolutifs (YANN LECUNN : 1988)
L'invention des réseaux de neurones récurrents et plus particulièrement des réseaux de neurones Long Short Term Memory - LSTM - (Sepp Hochreiter et Jürgen Schmidhuber : 1997 )
La rapide augmentation de la puissance de calcul des ordinateurs du à la baisse des prix de unité de traitement tels que les processeurs ou les cartes graphiques
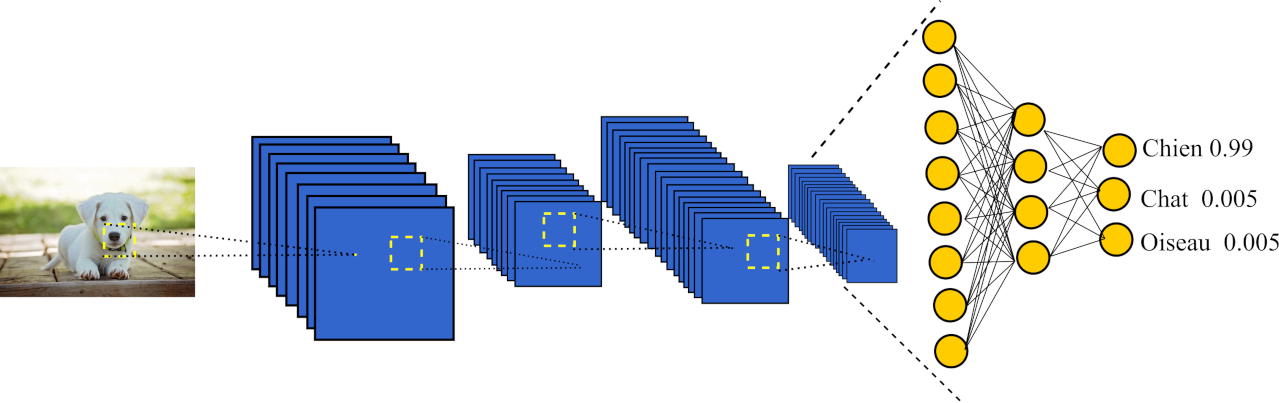
Les réseaux de neurones convolutif ont été inventés en 1988 par Yann LECUN un des trois pères fondateurs du deep learning à des fins de reconnaissance de chèques bancaires.
Ces réseaux sont principalement nés de la difficulté qu'avait la solution logicielle des laboratoires Bell à reconnaître l'écriture manuscrite sur les chèques bancaires.
Yann LECUN a alors fait face à une grosse difficulté : l'écriture manuscrite de chaque être humain est différente et peut être amenée à beaucoup varier d'un humain à l'autre.
Construire manuellement un modèle pour chaque type d'écriture est un travail très chronophage et peu gratifiant, il a alors l'idée de laisser l'ordinateur construire automatiquement ce modèle et donne naissance aux réseaux de neurones convolutif.
La particularité des réseaux de neurones convolutifs comparativement au technique de machine learning conventionnellement utilisés à l'époque (perceptron multicouches, JR48, Support Vector Machine etc....) est que ces réseaux sont capables de construire automatiquement à partir des données brutes un modèle mathématique capable d'extraire les informations contenues dans un signal (image, sont, vidéo, etc...) et de résoudre le problème de classification ou de régression posé.
Un fait intéressant des ces réseaux est que de manière générale, plus l'on rajoute de couches à ces réseaux (plus ils sont profonds) et plus les performances obtenues par ces derniers sont exceptionnelles.
Cela est une première explication à l'invention du terme "deep learning".
Le système de reconnaissance proposé par Lecun est rapidement devenu l'un des plus utilisés à l'époque aux États-Unis tant est si bien qu'en 2000 il est utilisé pour la reconnaissance de plus de 10 % du nombre total de chèques générés aux États-Unis.
Un peu plus tard, mais toujours dans les années 2000 les CNN explosent tous les benchmarks obtenus par les meilleurs algorithmes de machine learning.
Enfin en 2017, AlphaGo, une IA capable de jouer au jeu de go et utilisant des réseaux de neurones convolutifs, bat le champion du monde de go Ke Jie. Cet évènement marque un tournant sans précédent dans l’histoire de l’intelligence artificielle, car jusqu’alors aucune IA n’avait réussi à dépasser l’humain dans le jeu de go.
Voici un schéma du réseau convolutionnel de neurones
Les réseaux de neurones récurrents sont utilisés pour le traitement de série temporelle.
Ils peuvent être utilisés pour diverses applications telles que la prédiction du cours des d'actions, la reconnaissance vocale, ou encore la reconnaissance d'actions dans des vidéos.
Ce type de réseau se distingue d’autres types de réseaux neuronaux de par sa capacité à retenir les observations qui lui ont précédemment été soumises et à en déduire la réponse en fonction des informations extraites de ces observations.
Il est l'équivalent donc de la mémoire de travail à court terme que nous avons.

Schéma d'un réseau de neurones récurrents et de son déroulé
La particularité des réseaux de neurones récurrents est que les neurones peuvent être connectés à eux même comme le montre le schéma ci-dessus.
Lors de l'entraînement de ce type de réseau, plusieurs séries temporelles sont envoyées les une après les autres en entrée du réseau, le réseau est alors déroulé totalement afin de pouvoir calculer l'erreur et corriger les poids.
Lors de ce déroulement, le réseau devient alors très profond du fait de la grande taille de la série temporelle.
Cela explique également le pourquoi du terme "Deep Learning".
Si vous voulez en savoir plus sur ce type de réseau, vous pouvez lire cet article : Réseaux de neurones récurrents.
Pour chaque problème métier, selon les données métier, machine learning permet de construire un modèle mathématique qui pourra résoudre ces problèmes.
Prenons par exemple le cas d'une application de reconnaissance de fleurs.
Pour résoudre ce problème, en utilisant le machine learning, un ingénieur commencera par prélever sur les trois types de fleurs diverses mesures discriminantes telles que leurs aires, leurs périmètres, leurs nombres de pétales, etc...

Il enverra ensuite ces mesures à un algorithme de machine learning.
Généralement, ce sera un classifieur tel qu'un arbre de décision, une machine à vecteur support ou encore Adaboost.
Cet algorithme fournira en retour l'espèce de la fleur après entraînement comme montré sur le schéma ci-dessous.
